その1を見ていない人はその1から見始めることをお勧めします。
この記事の目次
格納されているべき情報を考える
複数ファイルをまとめたファイルを作る場合、最低限どのような情報が含まれているべきでしょうか?
これは用途にもよりますが、おそらく今回入っているだろうと推測される情報は以下のとおりになります。
- ファイル名
- ファイル格納アドレス
- 元ファイルサイズ
- 圧縮後ファイルサイズ
また、ファイルリストそのものの情報として、以下のようなものも必要でしょう。
- ファイルリストのアドレス
- ファイルリストのサイズ
- ファイルの個数
今回のファイルリスト編ではこれらの情報全てを見つけることを目標とします。
ファイル情報の境界線を調べる

srcから始まりtgaで終わっている文字列がほぼ確実にファイル名とわかるので、これを基点にして見ていきましょう。
まず各ファイル名の間のbyte数を数えてみると、全てきっちり20byteであることがわかります。
(ファイル名自体は可変長なようですが、その辺りはまた後で)
このことから、ファイル一つ辺りファイル名と20byteのデータが付いていることがわかります。
- ファイル情報
| addr | description |
|---|---|
| 0-? | 何かのファイル情報? |
| ?-? | ファイル名 |
| ?-? | 何かのファイル情報? |
次にファイル名の前後何byte目までがそのファイルに結びついている情報なのかを調べます。
ファイル末尾をみるとファイル名の後に8byteほどデータがくっついているのがわかります。
なので、ファイル名の前12byteとファイル名の後8byteがそのファイルの情報だと考えたくなりますが、
よく見てみるとどうやら違うらしいことがわかります。
まずファイル名の直後4byteを抽出してみると以下のようになります。
E4 69 00 00
3E 6C 00 00
75 6E 00 00
29 71 00 00
FB 73 00 00
B3 76 00 00
04 00 00 00
この並び方は明らかにリトルエンディアンなので、前後を前後を入れ替えると以下のようになります。
00 00 69 E4
00 00 6C 3E
00 00 6E 75
00 00 71 29
00 00 73 FB
00 00 76 B3
00 00 00 04
見てわかるとおり、徐々に増加傾向にあるそれなりに大きな数値であることがわかります。
ですが最後の4byteだけ明らかにその法則に反しており、不自然であることもわかるかと思います。
推測ではありますが、おそらくファイル末尾の8byteは個別のファイル情報とは関係のない情報であり、
ファイル情報はファイル名の前20byteということなのでしょう。
- ファイル情報
| addr | description |
|---|---|
| 0-19 | 何かのファイル情報? |
| 20-? | ファイル名 |
- ファイル末尾の何か
| addr | description |
|---|---|
| 0-7 | 何か情報? |
ファイル末尾8byteを調べる
どうやらファイル末尾8byteが個々のファイルに言及したものではなさそうということはわかりました。
冒頭で挙げた情報のうち、ファイルそのものに関係しない情報といえば
- ファイルリストのアドレス
- ファイルリストのサイズ
- ファイルの個数
の三つです。
では、8byteの中にこれらに該当するような情報が含まれていないか見ていきましょう。
目で見て数えたところ、上記三つの実際の値は
ファイルリストアドレス:0x0001E440
ファイルリストサイズ:0x07CF(1999byte)
ファイル個数:0x2B(43個)
でした。
そして、ファイル末尾の8byteは
04 00 00 00 0F 79 00 00
です。
予想外なことに、そのものずばりな数値はおろか近似値すら見当たりません。
ですが、他の情報が格納されているとも考えづらいため、何分の一かに除算された値である可能性を考えます。
たとえば、一般的な32bitCPUのOSが4GBのメモリーを管理するさい、領域を64KBごとに切り分けて2byteでサイズやアドレスを表現できるようにしているのと同じで
0xFFFFFFFFを超える表現を扱うが4byteで表現したい場合に4~64程度で除算された値が格納されていることがあります。
ファイル末尾8byteはおそらく30991(0x790F)と4の二つに分けられるように見えるので、これらの数値で除算してみましょう。
- 割る4
ファイルリストアドレス:0x7910(30992)
ファイルリストサイズ:0x01F3(499)余り3
ファイル個数:0x0A(10)余り3
- 割る30991
ファイルリストアドレス:4余り4
ファイルリストサイズ:0余り1999
ファイル個数:0余り43
ファイルリストの先頭アドレスが非常に近い値をとっています。
またずれているのもたった4byteなのとファイルリストが伸びる方向なので
何か一つ二つ情報が格納されていると考えれば十分にありうる範囲です。
おそらく、ファイル末尾4byteはファイルリストの先頭アドレスを4で割った数値と思っていいでしょう。
また、4といえばすぐ横のファイル末尾4~8byte目に格納されていた数値でもあります。
おそらくですが、アーカイバ内でアドレス表記をするにあたって、何分の一の値を用いるか、という設定データなのではないかと思われます。
このファイル自体は4GBには遠く及ばないので本来ならば1が設定されているべきにも見えますが、おそらく実装の都合というやつなのでしょう。
- ファイル末尾の8byte
| addr | description |
|---|---|
| 0-3 | アドレス表現の分母 |
| 4-7 | ファイルリストの先頭アドレス |
残りの情報を調べる
ファイルリストの先頭アドレスがわかったので早速見に行って見ましょう。
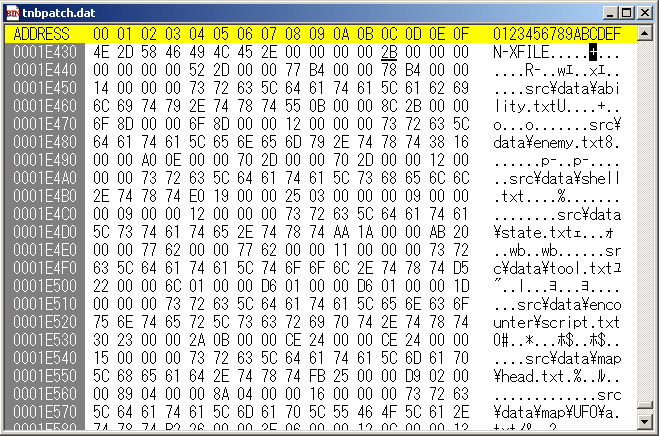
黒いカーソルが表示されている0x0001E43Cがファイルリストの先頭になります。
ただし、前章でも書いたように個々のファイルリストは0x0001E440から始まるので、0x0001E43C~0x1E43Fまでは個々のファイル情報ではないもののはずです。
これもまた前章で書いたようにファイル個数を手動で数えたものが0x2B(43個)でした、値が一致していることから見てファイル個数と見ていいでしょう。
- ファイルリスト
| addr | description |
|---|---|
| 0-3 | ファイル個数 |
| 4~X | ファイル情報の配列 |
これで個々のファイルに関係しない情報三種は全て判明しました。
(アドレスと個数は言うまでもなく、ファイルリストのサイズもアドレスとファイル全体のサイズから計算可能です)
では個々のファイル情報に行きましょう。
- ファイル情報
| addr | description |
|---|---|
| 0-19 | 何かのファイル情報? |
| 20-? | ファイル名 |
- 未判明情報
- ファイル格納アドレス
- 元ファイルサイズ
- 圧縮後ファイルサイズ
まずファイル情報が可変である謎を解きます。
ファイル名をよく見ると終端記号(\0)がありません。
という事は、ファイル名の長さが明示されていなければ読み込むことが出来ないことになるので、20byteのうちどれかがファイル名のbyte数のはずです。
実際調べてみれば全てファイル名の直前4byteがファイル名の長さと一致していました、これがファイル名の長さでしょう。
- ファイル情報
| addr | description |
|---|---|
| 0-15 | 何かのファイル情報? |
| 16-19 | ファイル名の長さ |
| 20-X | ファイル名 |
次はファイルの格納アドレスを調べましょう。
その1で書いたように、このデータファイルは1byte目から格納ファイルの本体が始まっていました。
ということは、一つ目のファイルではファイル格納アドレスに0が入っているはずです。
実際ファイル情報の先頭に当たる0x0001E440を見ると0x00000000が格納されてました、以前ここの情報が徐々に増加していく傾向があったのもファイルの格納アドレスと考えれば説明が付きます。
ですが、一番最後のファイルでもここに設定された値は0x000076B3と、データファイル全体の1/4にも満たない値をとっています。
実際いくつかのファイルで4倍したアドレスを見てみれば、明らかにそこがファイル先頭だとわかるものばかりでした。
おそらくファイルリストの先頭アドレスと同じように1/4された値が格納されているのでしょう。
- ファイル情報
| addr | description |
|---|---|
| 0-3 | ファイル格納アドレス |
| 4-15 | 何かのファイル情報? |
| 16-19 | ファイル名の長さ |
| 20-X | ファイル名 |
次に圧縮後ファイルサイズ。
これは前後のアドレスの差と近似している値を探すだけなので簡単です。
先頭から一番目はアドレス0x00000000、二番目のアドレスは0x00000B55なので0x00000B55*4-0x00000000*4=0x00002D54となり
ちょうどファイル情報4byte目から4byteと一致します。
これが圧縮後ファイルサイズでしょう。
- ファイル情報
| addr | description |
|---|---|
| 0-3 | ファイル格納アドレス |
| 4-7 | 圧縮後ファイルサイズ |
| 8-15 | 何かのファイル情報? |
| 16-19 | ファイル名の長さ |
| 20-X | ファイル名 |
最後にファイルサイズです。
ですがもはや残っているのはたった8byteな上、前半4byteと後半4byteが全てのファイルで佐賀0~3以内の近似値を取っています。
また、後半4byte側が必ず前半4byte以上の値をとっています。
推測ですが、圧縮方法の都合で末尾に多少不要なデータが付着してしまうため、その不要データ込みのサイズと実際のサイズの二種類があるのでしょう。
要するに、前半4byteがファイルサイズで、後半4byteが解凍時使用スペースとなります。
- ファイル情報
| addr | description |
|---|---|
| 0-3 | ファイル格納アドレス |
| 4-7 | 圧縮後ファイルサイズ |
| 8-11 | ファイルサイズ |
| 12-15 | 解凍時使用スペース |
| 16-19 | ファイル名の長さ |
| 20-X | ファイル名 |
その2まとめ
- ファイル末尾の8byte
| addr | description |
|---|---|
| 0-3 | アドレス表現の分母 |
| 4-7 | ファイルリストの先頭アドレス |
- ファイルリスト
| addr | description |
|---|---|
| 0-3 | ファイル個数 |
| 4~X | ファイル情報の配列 |
- ファイル情報
| addr | description |
|---|---|
| 0-3 | ファイル格納アドレス |
| 4-7 | 圧縮後ファイルサイズ |
| 8-11 | ファイルサイズ |
| 12-15 | 解凍時使用スペース |
| 16-19 | ファイル名の長さ |
| 20-X | ファイル名 |
以上のようにファイルリストの解析は完了しました。
次からはいよいよファイル本体の解析に着手します。