THxxBGMに憑依華製品版の曲再生機能を足すアプリを作りました(引き続き深秘録と心綺楼も増える)。
http://wordpress.click3.org/garakuta/thxxbgmTh155Patch.zip
使い方は、中のwinmm.dllをTHxxBGM.exeと同じディレクトリに置くだけ。
うまいこと行けばpath設定に憑依華と深秘録と心綺楼が増えて、該当ディレクトリを設定すれば聞けるようになるはず。
THxxBGMに憑依華製品版の曲再生機能を足すアプリを作りました(引き続き深秘録と心綺楼も増える)。
http://wordpress.click3.org/garakuta/thxxbgmTh155Patch.zip
使い方は、中のwinmm.dllをTHxxBGM.exeと同じディレクトリに置くだけ。
うまいこと行けばpath設定に憑依華と深秘録と心綺楼が増えて、該当ディレクトリを設定すれば聞けるようになるはず。
駄文、もしくはポエムの類だ、嫌いな人はスルーしてほしい。
以降の記述はすべて”情報科学においては”と装飾されているものとする。
また一個人の考えであり、正しさを保証するものではない。
まず世間においては以下のような考えを主張する人が多くいる。
「ほとんどの問題はすでに解決した人がいるので、試行錯誤したら1時間かかることも探せば10分で答えが見つかる、だから試行錯誤は最低限に抑えるのが上達のこつだ」
これは自分も複数人から実際に聞かされているし、大体の場合は正しいと思う。
しかし自分は正しくないこともあると考えている、それも結構な確率で。
前提として探しても答えが見つからない場合にどうするかを考える。
もちろん組み合わせ爆発的な問題があるので実際試せばわかる程度のものは含めない、もっと根本的にそれが何かすらつかめていないレベルのものだ。
「ほとんどの問題はすでに解決した人がいる」を前提に話している以上は探し方が悪いと言いたいのだろう。
なので「答えを見つけられる探し方を探す」方向に進むか「解決不能な問題である」と諦めるべき、ということだと思う。
以降はこの前提を置いて進める。
では本題として前述の主張に対する欠陥を指摘する。
「ほとんどの問題はすでに解決した人がいる」が事実だとしても「解決しても公開する人は圧倒的少数派である」ことが抜けている。
例を出そう。
「ゲームコントローラーの入力を受けて、フォーカスが当たっているゲームに、任意のキーボードイベントを送りたい」という問題を考える。
これはjoytokeyというアプリで実際に解決されていて、具体的な方法はWin32APIのkeybd_eventの極一部のドキュメントにしか記載がないbScanという隠し機能を使うというものだ。
では、探すだけでこの具体的な方法にたどり着けるだろうか?
2018/01/18のgoogleによれば「joytokey」では260,000件あるが「joytokey keybd_event」では244件で「joytokey keybd_event bScan」は20件、実際に記載があったのは2件で、どちらも無関係な第三者が調べた結果だ。
試行錯誤なしにこの情報にたどり着くのは常人では難しいだろう、少なくとも自分だったら無理だ。
このように明確に解決した人がいても公開しないことは普通なのだ。
公開されないと何が問題かと言えば、誰かが解決済みでも自分は解決できないことが多数発生することだ。
少し考えればわかるだろう、ソース非公開の素晴らしいアプリがあったとしてそれを100%模倣することなど普通は出来ないのだから。
普段探して解決している問題は解決した人がたくさんいるから公開する人も多かっただけに過ぎない。
つまりほとんどの問題は探して解決するなどというのは幻想で、探すだけでは解決しない問題は大量に存在しており、ただそういう問題は直面する確率が低いだけなのだ。
そして1%の事象でも100個集まればそれなりに踏むように、これらの問題のどれかは結構な確率で踏む。
そんな時に毎回諦めるのは本当に良いことだろうか?そうして得られる知識だけで本当に上達したと胸を張れるのだろうか?
自分は違うと思う。
成長とはその技能そのもの以外にも、その技能関連問題をどれぐらい解決できるかも含むと自分は思っている。
なので、誰も教えてくれない知識に自力でたどり着けるようになることも成長だと思う。
もちろんたどり着けるようになる方法そのものを探して身に着けるということは否定しない。
しかしプログラミングなどのように実践しようと思えばいくらでも実践できる分野ではないので、ある程度は都度試行錯誤していくのがベターだと思う。
さすがに毎回探す前に試行錯誤するようでは問題あるとは思うが。
以上、試行錯誤しないと手に入らない知識ばかり気になってここまで来たのに否定されまくったことの愚痴でした。
ちなみに初手試行錯誤も自分は否定しない。
0から試行錯誤した経験はその知識に対して多角的視点を与えてくれる(プログラミング作業では車輪の再発明とも呼ぶ)。
コストが高すぎるので全てで行うことは馬鹿げているが、一切やらない人はそれはそれで愚かだと思う。
なので試行錯誤は用法用量を守って正しく行いましょう、というお話だったとさ。
Splatoon1ではロングブラスターこそが最優のブラスターなのだが(※感じ方には個人差があります)
いまいち人気がなくSplatoon2にも実装されないので適当に駄文を貼る。
まぞこの表を見てほしい。
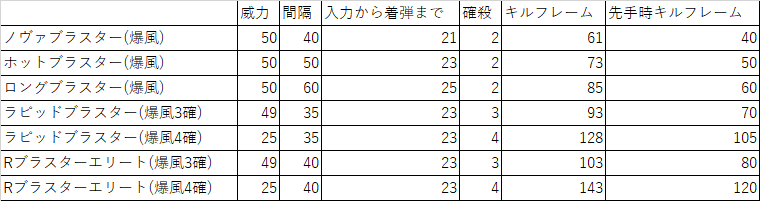
重要なのは「先手時キルフレーム」で、奇襲に成功した後に敵に残された猶予だ。
wikipediaを見ると反応に約10フレームかかると見込め
感度最高で背後を向くことだけ考えてコントローラーをブンブンしても平均22フレームかかったので敵がエイム合わせるのに22msはかかると思え
中距離キル最速のスプラシューターはキルフレーム13である。
なので奇襲すると反撃には10+22+13=45フレームは絶対にかかると見込める。
上記を踏まえてカラムを足したのがこちら。

ノヴァブラスターは文句なしで確殺
ホットブラスターも奇襲予知クラスの化け物以外は確殺
ロングブラスターは一切動揺せずエイムが一瞬で合うレベルの使い手以外は確殺
ラピッドブラスターは大幅有利ではあるが負けうる
ラピッドブラスターエリートはただ有利なだけだろう
このように、動き回って先手を取る戦法において確殺と呼べるのはぎりぎりロングブラスターまでだ。
なので、中距離まで接近する立ち回りではロングブラスターとラピッドブラスターの間には超えられない壁のようなものが存在する(そもそもラピッドではそこまで近づかないが)。
一方でロングブラスターは劣化はするがラピッドブラスターの立ち回りも出来る。
なのでロングブラスターとは、ホットブラスターとラピッドブラスターを足して1.7割ったような武器なのだ。
つまりロングブラスターこそ最優のブラスター(※感じ方には個人差があります)、皆ももっと使ってSplatoon2運営に実装圧力をかけよう!
タスクバーアイコンの音量から音量ミキサーを開いたところにあるアプリ別のアレです。
ライブラリやデバイスの都合で音量を調整できないことがありますが、それを無理にでもなんとかする際に便利です。
ではいつものようにコード本体からどうぞ。
http://resemblances.click3.org/product_list/index.cgi/detail/88
http://wordpress.click3.org/garakuta/volum_mixer_example.zip
動作としてはWindows付属の効果音を鳴らしっぱなしにしつつ、音量をひたすら上下させるだけのアプリになります。
また、サンプルの機能をそのままライブラリ化したものもあるので別途貼っておきます。
http://resemblances.click3.org/product_list/index.cgi/detail/87
http://wordpress.click3.org/garakuta/volume_manager.zip
音量調整にはCOMを使用しています。
特別COMに関する説明はしませんので、COMとは何かを知らない場合は理解が難しい可能性があります。
またインスタンスの解放処理など本質的ではないコードも除けてあるので、サンプルそのままでの使用は非推奨です。
自身のコードに組み込む場合はvolume_managerの方を参照してください。
非同期で効果音をループ再生
=>音声デバイスを取得
=>そのデバイスのセッション管理インスタンスを取得
=>セッションを列挙
=>セッションのプロセスIDを取得、自身のプロセスIDと一致する物を探索
=>音量を調整
となります。
::PlaySoundW(L"C:\\Windows\\Media\\ringout.wav", nullptr, SND_ASYNC | SND_FILENAME | SND_LOOP);
単にPlaySoundしているだけです。
IMMDeviceEnumerator *deviceEnumerator; ::CoCreateInstance(__uuidof(MMDeviceEnumerator), nullptr, CLSCTX_INPROC_SERVER, IID_PPV_ARGS(&deviceEnumerator)); IMMDevice *device; deviceEnumerator->GetDefaultAudioEndpoint(EDataFlow::eRender, ERole::eMultimedia, &device);
CoCreateInstanceのあたりは説明不要ですね。
GetDefaultAudioEndpointは名前の通りデフォルトのデバイスを取得するもので、eRenderはスピーカなどの出力、eMultimediaは何らかのコンテンツ再生用を意味しています。
IAudioSessionManager2 *sessionManager; device->Activate(__uuidof(IAudioSessionManager2), CLSCTX_INPROC_SERVER, nullptr, reinterpret_cast<void **>(&sessionManager));
これも特に説明はいらないですね。
単にActivateメソッドを呼んでいるだけです。
なお、ここでいうセッションは「アプリの音量セッション」とでも呼ぶべきもので、音量出力APIを利用した後で現在も生きているプロセスに紐づく音量管理セッションのことです。
音量再生系APIを呼んだ後でなくては生成されないので注意が必要です。
IAudioSessionEnumerator *sessionEnumerator;
sessionManager->GetSessionEnumerator(&sessionEnumerator);
unsigned int count;
sessionEnumerator->GetCount(reinterpret_cast<int *>(&count));
for (unsigned int i = 0; i < count; i++) {
IAudioSessionControl *session1;
sessionEnumerator->GetSession(i, &session1);
IAudioSessionControl2 *session;
session1->QueryInterface(&session);
...
}
GetSessionEnumeratorの返り値がセッションの個数取得とセッション取得メソッドがあるので、それをforで回して取得しています。
IAudioSessionControlにはプロセスIDのようなプロセスと紐づけられる情報がないのでIAudioSessionControl2にQueryInterfaceしています。
DWORD processId;
session->GetProcessId(&processId);
if (processId != ::GetCurrentProcessId()) {
continue;
}
これも説明はいらないですね、みたままです。
ISimpleAudioVolume *audioVolume;
session->QueryInterface(&audioVolume);
unsigned int volume = 0;
while (true) {
if (volume <= 100) {
audioVolume->SetMasterVolume(static_cast<float>(volume) / 100, nullptr);
} else if(volume < 200) {
audioVolume->SetMasterVolume(static_cast<float>(200-volume) / 100, nullptr);
} else {
volume = 0;
}
::Sleep(10);
volume++;
}
ISimpleAudioVolumeへQueryInterfaceし、あとは10msごとにSetMasterVolumeする無限ループなだけです。
ここにはないですがGetMasterVolumeやSetMute/GetMuteといったメソッドも存在します。
上手くいけばここで音声が上下に波打つようにして流れ続けるはずです。
必要最低限程度ですがこれでアプリ別音量の設定ができます。
ここには書いていませんが少し呼び方を変えれば対象デバイスを指定して同様の処理を行ったりマイク音量の調整といったことも可能です。
あとは必要に応じて該当するインターフェースのドキュメントを参照してください。
最近Splatoonにはまっていまして、命中率について実際に計測しました。
せっかくなので結果をまとめて公開しようかと思います。
※追記:命中率表に信頼区間追加しました
測定対象はオーソドックスにシューター13種だけ、またブラスターは対象外とした。
測定する距離は各武器の最大射程である1.5/2.2/2.8/3.1/3.6/4.5(試し撃ち場の点線一個分を1換算)の6種類。
ジャンプによる命中率の低下については今回は対象外。
距離の決定方法は、試し撃ち場にて線が引いてある広場の一番奥の人形相手を対象とし
その距離が最大射程である武器にて、照準が変化せず、なおかつ撃った際のイカ人形へのヒット位置があまり下すぎない程度に目視にて調整。
目視なため距離精度は高くないけれど、その場で武器持ち替えが可能なので、それを駆使して出来るだけ同一の距離で計測するように配慮した。
ただし、もともとは別の計測目的だったことや、計測中にH3リールガンの追加があったこと、WiiUの電源落ちてしまう事故があったなどで同一距離ではない計測も含まれている。
実際の計測方法は、1000発以上撃ちこんでその間に外れた回数を数えるという方法。
トリガーを引いたままでは目視による計測が難しかったため、1発だけ弾を撃ち着弾したかどうかを確認し再度1発だけ撃つを繰り返す形で行った。
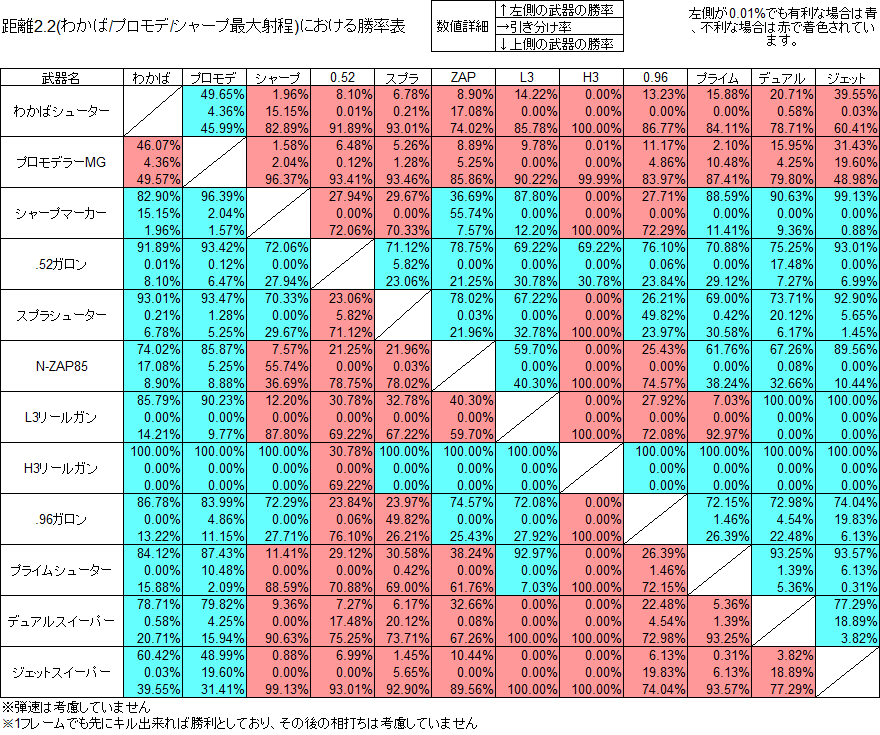
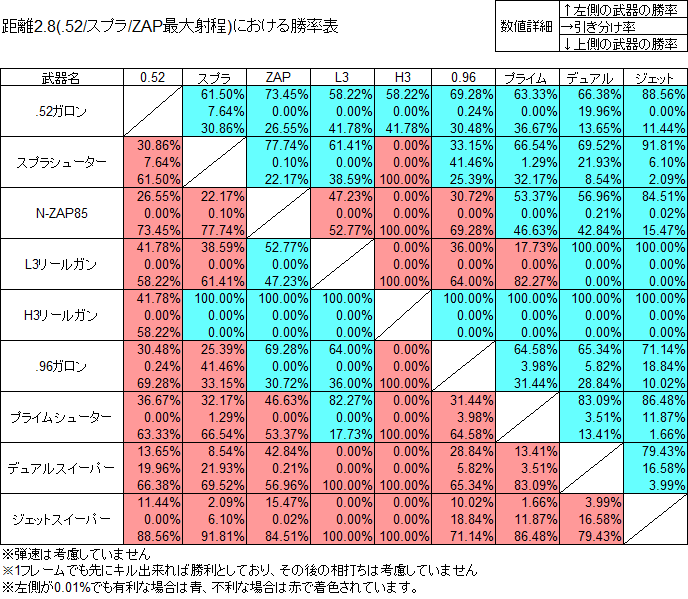
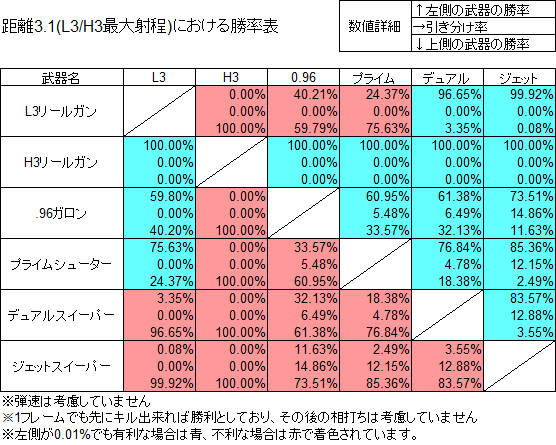
また計測結果を元に命中率、Killを取るのに必要な射撃数の平均、各武器間での勝率計算、勝率有利がつく武器の数のカウントなどを行った。
勝率計算は弾速を考慮せず、1フレームでも先に相手をKill出来れば勝利、同一フレーム内なら引き分け、それ以外なら相手の勝ちとした。
なので通常であれば発射後着弾前の弾により相打ちとなる場合でもどちらかの勝利として数えられていることになる。
当然のことだが、機械的な計測ではなく完全な人力での計測なため、ある程度計測ミスが含まれていると思われる。
そのあたりを理解したうえで結果を読んでもらいたい。
まずは命中率の表
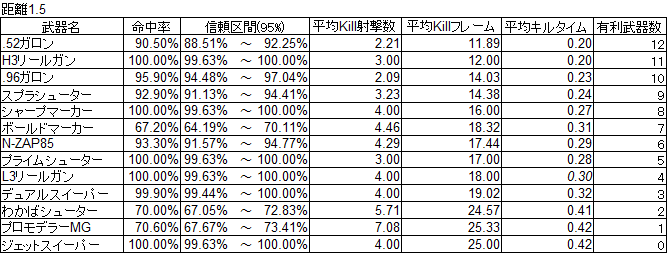
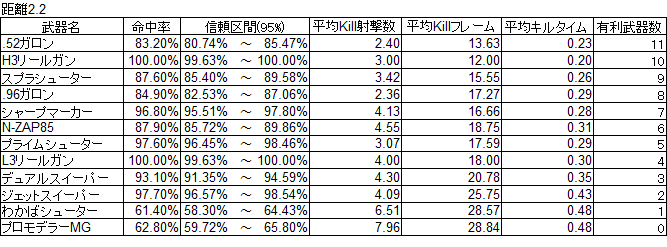
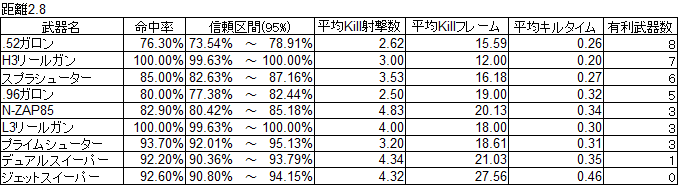
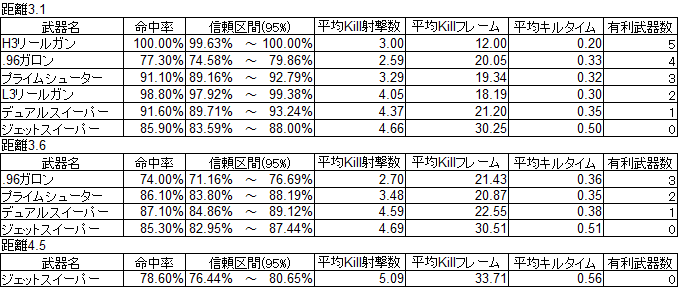
次に勝率の表

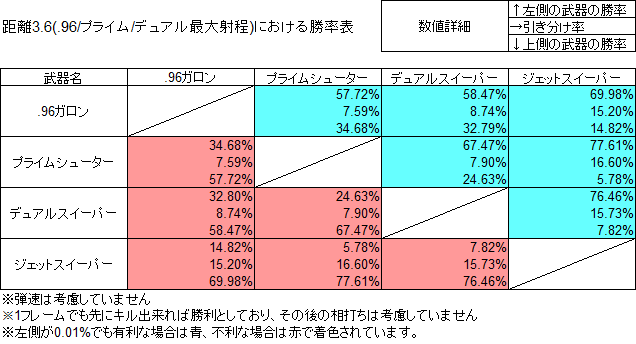
※※※ここから先は読まなくて大丈夫です※※※
計測を始めた時点ではwikiの拡散値から具体的にどの程度の命中率になるのかを調べるぐらいのつもりだったのですが、実際に計測してみれば
拡散値的には4.5対6で1.5も勝ってるはずの.96対スプラで.96が命中率で負けてる距離があったり
0.5しか差がないデュアルと.96で凄い差がついたり
逆に1違うはずのデュアルとプライムがほぼ同じ命中率だったり
と、明らかに現状の拡散値だけでは説明できない事象が多数観測されました。
これは現状のwikiに載っている拡散値が間違っているか、それと拡散値以外に何か命中率を大きく左右する要素があるか、といった話になります。
このあたりの情報持ってる人だれかいませんかね?
最終的な結果だけ見れば、概ね体感通りかなという印象ではありました。
たとえばボールドマーカーはカタログスペックよりはだいぶKill性能は低めである点、シャープマーカーは短射程組の中では飛びぬけてKill性能が高い点、.96ガロンはスプラシューターと同じぐらいな点などです。
これを新発見に乏しい無駄な計測だったとするか、体感通りの結果が数値付きで示された良い計測だとするかは皆様の判断に任せます。
一部平均Killタイム通りに有利不利がついていない武器がありますが、これはちゃんと「n発撃つのにかかる時間内に敵に撃ち殺される確率」のような計算をしているからです。
平均Killタイムが悪くても最速Killタイムが早ければ気持ち有利がつきやすいなどなど。
高速高威力かつ低命中率のボールドマーカーなんかがわかりやすいですね。
L3リールガンとH3リールガンで命中率に特に差はないと感じていますが、実際の計測結果としてはL3だけわずかに外れるという形になっています。
ですが、実はL3リールガンの距離3.1計測が全体で一番最初に行った計測で、つまり自分の計測経験値が足らなかったためイカ人形復活直後の判定なし状態で撃ちこんでしまったとか、そういう計測ミスの可能性があります。
しかし、そういった理由をつけて計測結果を取捨選択することは統計的にはやってはいけないことなので、最終的にはそのままの数値で出すことにしました。
元気があればL3リールガンだけ3000回ぐらい追加計測して最初の計測がおかしいかどうか検証してみたいですね。
より詳しい計測順序の話をすると
各武器で射程最大から撃った場合の命中率だけ計測しようと考えて計測、その結果をtwitterに投げる
しかし最大射程のしかないため射程が違う武器同士ではどちらが命中率が高いとか撃ちあった場合どちらが強いとかいう計算が出来ない
なら距離を揃えた計測もやろう!ということで今回の計測が始まりました。
29,000発以上イカ人形に撃ちこんだ計算になります、大変だった。
ちなみに、最大射程での計測結果はそのまま今回の計測に使いまわしているため、その距離が最大である武器だけ他とは微妙に違う距離で計測していることになります。
東方系dat展開ツールtouhouSE更新しました。
http://wordpress.click3.org/garakuta/touhouSE.zip
東方深秘録対応版です。
完璧主義が発動して、1方向hashからファイル名を逆算する作業に明け暮れたため、3週間ほど出すのが遅れました。
その甲斐あって98%のファイル名は判明しているので、その周りでは特に困ったりはしないと思います。
THxxBGMに深秘録製品版の曲再生機能を足すアプリを作りました(一応心綺楼も増える)。
http://wordpress.click3.org/garakuta/thxxbgmTh145Patch.zip
使い方は、中のwinmm.dllをTHxxBGM.exeと同じディレクトリに置くだけ。
うまいこと行けばpath設定に心綺楼と深秘録が増えて、該当ディレクトリを設定すれば聞けるようになるはず。
後置インクリメントと前置インクリメントは基本的に前置の方がよいそうですが、自分は後置の方が書きやすくて好きなので、どこまでなら後置でもいいのか検証する目的で速度を測ってみました。
検証に使用したコンパイラのバージョン:
VisualStudio C++ 19.00.22609 for x86
gcc (GCC) 4.8.1
clang version 3.6.0 (tags/RELEASE_360/final)
検証環境はWindows10 TechnicalPreview
典型的なfor文を前置後置それぞれのインクリメントを使用する形で作成。
インクリメント対象をunsigned int/iterator/適当に重めのクラスの三種それぞれを対象。
また、最適化により返り値計算が消えることを考えforの真偽判定でインクリメントの返り値を使用するものも用意。
以上をそれぞれ100,000,000回実行をさらに10回繰り返しかかった時間の平均をとる。
また、比較用に拡張forにてループまわすだけのも計測。
具体的なソースコードとコンパイルオプションは以下を参照。
ソースコード
コンパイルに使ったバッチファイル
以下読み飛ばしても通じる、検証をこの内容にした理由やらなんやら:
インクリメント演算子と言えば基本的にループで使用することが多いはず。
まれに+=1の代わりに使うこともありますが、それで行いうる処理はループも全て含んでいるでしょう。
他にも演算子オーバーライドなどでクラス独自に定義して使うこともあるかもしれませんが
そこまで行くと後置不利の根拠である値コピーがどーたらという前提すら崩れかねないですし
そもそも滅多にあるものでもないので今回は除外しました。
また、普通にforをまわすだけだと最適化で消え去ってしまうし、ある程度最適化を妨げようとすると今度はforが誤差になるぐらい処理速度を持って行かれてしまいます。
なので、インラインアセンブラでNOPを突っ込むことで対応。
それでもintのインクリメントをデクリメントに置換されたりいろいろしていますが、それは通常利用でも起きうるものとして許容しています。
クラス作成もいろいろ大変で、単にintをラップしたようなのを書くと当然ながら全部インライン展開されてint直と同じレベルまで最適化されてしまいます。
ですが、今回は後置の不利を検証するためなので残す必要があり、いい具合に重い処理として乱数を生成させました。
とはいえ乱数処理は重すぎるので1/1000しか動かないコードが入っています。
ちなみに、最適化の抑止の大変度合はclang>gcc>vcでした。
vcはNOP入れた以外では全部素直なコードを吐いて順当に遅かったです。
gccはクラスのインクリメントにて使いもしないメンバー配列をstd::copyしたら順当に遅くなりましたが、clangはそれすら最適化で消し去りました。
つまりclangが一番最適化は賢い、と思ったら最終的な計測結果ではgccに負ける感じに、詳しくは結果欄をどうぞ。
| vc++ | gcc | clang | |
|---|---|---|---|
| 拡張for | 57ms | 53ms | 48ms |
| int前置インクリメント | 46ms | 61ms | 41ms |
| iterator前置インクリメント | 47ms | 47ms | 45ms |
| クラス前置インクリメント | 320ms | 47ms | 316ms |
| int前置インクリメント、返り値使用 | 44ms | 47ms | 46ms |
| iterator前置インクリメント、返り値使用 | 44ms | 37ms | 46ms |
| クラス前置インクリメント、返り値使用 | 317ms | 51ms | 313ms |
| int後置インクリメント | 51ms | 44ms | 53ms |
| iterator後置インクリメント | 51ms | 50ms | 46ms |
| クラス後置インクリメント | 2206ms | 388ms | 446ms |
| int後置インクリメント、返り値使用 | 55ms | 50ms | 50ms |
| iterator後置インクリメント、返り値使用 | 97ms | 50ms | 54ms |
| クラス後置インクリメント、返り値使用 | 2253ms | 458ms | 431ms |
まず独自クラスは前置と後置で明らかに結果が異なり、後置が圧倒的に遅いです。
最小のclangでも1.5倍、最大のgccだと実に約9倍。
もちろんこれはコピーコンストラクタの重さに依存しますが、ある程度以上のクラスであれば必要のない後置インクリメントは避けた方がよさそうです。
また、地味ですがvc++のみ返り値使用の後置iteratorが前置の約2倍かかっています。
vc++においてはまだ「iteratorは最適化すれば消え去る」は幻想のようですね。
返り値の使用有無による変化は例外を除いて後置のクラスでのみでした(例外:前述のvc++後置iterator)。
おそらくintやiteratorであれば最適化の結果前後が消え去り、通常のメモリ=>レジスタ移動の範囲で解決できてしまうからでしょう。
なぜかgccだけクラス使用時の速度がとても速いです。
が、試行錯誤している間はずっとclangの方が速かったので、偶然今のコードではインスタンスが全部レジスタに載ったとかだと思われます。
ただしvc++がクラス使うと遅いのは最初から最後まで一貫していたので、この三つの中で一番遅いことは確定してよさそう。
他は特に速度の変化は見られません、また拡張forとの速度差も見られません。
なので、後置インクリメントでもプリミティブ型かiteratorなど薄いラッパークラスであれば速度に影響が出ることはない、と言っていいと思います。
(例外:vc++で後置インクリメントの結果を使う)
それ以外で後置インクリメントを使うこと自体そうあることではないですし、別に後置インクリメントをつける癖がついていても害はないと言っていいでしょう、あーよかった。
前回せっかくclangやgccの環境を整えたので、以前から気になっていたインクリメントの速度計測をやってみました、いかがだったでしょうか。
個人的には後置の方が書きやすくて好きなので、現代の最適化の力を使えば特に害はなさそうとわかって一安心でした。
次はまた何かの速度計測をやるかもしれませんし、何かアプリ作るまで放置かもしれません。
ではまた。
本の虫さんの記事にて
linux上のGCCではただ別の関数へフォワードするだけの関数をコンパイルしてもPICが有効だとjmp一文にならない事とその理由を説明した記事を翻訳したものが載った。
そこでふと疑問に思ったのだが、PICとか関係のないwindows上ではどうなっているのだろうか?
というわけで、GCCとclangとVisualStudio2015それぞれでコンパイルして結果をまとめてみた。
なお、最適化の結果消え去るならば問題ないはずとの考えから最適化OFF/ON両方で検証している。
検証に使用したコンパイラのバージョン:
VisualStudio C++ 19.00.22609 for x86
gcc (GCC) 4.8.1
clang version 3.6.0 (tags/RELEASE_360/final)
まずは検証に使うソースコードを載せる。
main.cpp
#include <iostream>
void OtherFile();
void TailProc();
void NormalProc() {
std::cout << "Normal\n";
}
void CheckOtherFile() {
OtherFile();
}
void CheckTailProc() {
TailProc();
}
void CheckNormalProc() {
NormalProc();
}
void TailProc() {
std::cout << "Tail\n";
}
int main() {
CheckOtherFile();
CheckTailProc();
CheckNormalProc();
return 0;
}
lib.cpp
#include <iostream>
void OtherFile() {
std::cout << "OtherFile\n";
}
一応解説しておくと、CheckOtherFileは定義が別の.cpp、CheckTailProcは同じ.cppだが後方で宣言、CheckNormalProcは前方で宣言となっている。
コンパイルに使用した.bat
cl /EHsc /Ox /GL /Fevc_exe.exe main.cpp lib.cpp cl /EHsc /Od /Fevc_exe_O0.exe main.cpp lib.cpp g++ -O3 -flto -o gcc_exe.exe main.cpp lib.cpp g++ -O0 -o gcc_exe_O0.exe main.cpp lib.cpp clang++ -O3 -o clang_exe.exe main.cpp lib.cpp clang++ -O0 -o clang_exe_O0.exe main.cpp lib.cpp
clangのみ手元ではリンク時最適化できなかったため通常の最適化のみ。
最適化OFFの場合
main

各チェック関数
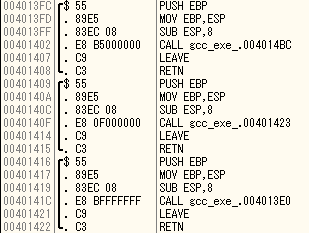
mainでなぜかcallが四つあるが一つ目おそらくコンパイラがつけた特殊関数だと思われる。
問題のcheck部分は元の記事ほど悪くはないがjmp命令ひとつまで縮んでいない。
最適化ONの場合
main
各チェック関数は三つとも完全にインライン展開されている。
最適化OFFの場合
main

各チェック関数
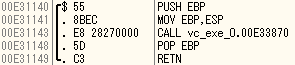
チェック関数は三つともほぼ同じだったため他二つは割愛。
最適化ONの場合
main
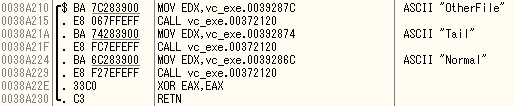
三つとも完全にインライン展開されている。
最適化OFFの場合
main
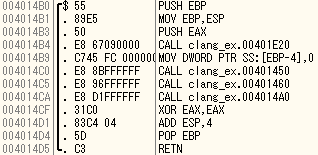
各チェック関数
mainの一つ目のcallはgccと同じくコンパイラが付与したもの。
チェック関数は三つともほぼ同じだったため他二つは割愛。
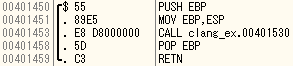
最適化ONの場合
main

OtherFileだけインライン展開されていないが、それは前述のとおりリンク時最適化が入っていないためと思われる。
CheckOtherFile自体はインライン展開されている。
windows上だとVC++/gcc/clangのどれであっても、フォワードするだけの関数をjmp一文に翻訳してくれたりはしない。
だが、最適化を有効にすればどのコンパイラでも、別の.cppでも同じ.cppでも、大体インライン展開されてほぼコスト0になるので気にする必要はほぼない。
VC++ではjmp一文にならないのは知っていたが、記事を読んだ範囲ではgccがjmp一文に翻訳するとしかおもえなかったため、コンパイラ比較にいい題材だろうと試してみた結果
このようなどれも結果がほぼ一緒で大した価値のない比較記事が生まれることとなりました、なんてこったい。
一応clangが文字数情報を生成してくっつけてくれてるとか、VC++はmainはほぼ書いたまんまだけどその他は前後にちょっと追加があるとか、clangのフォワード関数部分はgccではなくVC++寄りだとか、見どころはないでもないが全部本題とは無関係である。
まぁ、可読性のために別関数にしたりするぐらいではそう滅多にオーバーヘッドは生まないことが分かっただけでも収穫だろうか。
なにか間違いなどありましたらコメントください。
ではまた。
Windows8.1 updateから入ったセキュリティー機能であるControl Flow Guard(以降GuardCF)について調べたのでまとめておきます。
本記事を書く上で、以下のサイトを参考にさせていただきました。
http://www.ffri.jp/blog/2015/01/2015-01-05.htm
IMAGE_OPTIONAL_HEADER32など本稿にあまり関係のない部分については特に解説しないので、必要なら別途ググるなどしてください。
ざっくりと説明すると「呼び出す関数が実行時に決定されるコードから呼び出せるアドレスをホワイトリストで管理し、それ以外を実行しようとしたらクラッシュする機能」です。
たとえばC++の仮想関数、dllを動的リンクした際のGetProcAddressの返り値、関数ポインターを経由した呼び出し、などなどが対象。
主に、仮想関数テーブルを上書きすることで仮想関数実行時に任意のアドレスを実行させる、俗にいうvtable overwriteを防ぐための機能です。
パスの解析やらは一切やっておらず、バグか脆弱性がない限りここではAは呼ばれないと自明な場合でも、Aがホワイトリストに入っていればAの呼び出しを許可してしまいます。
おそらくこれは速度的な都合か、キャストを駆使されると確実な追跡が難しいというあたりかと。
また、仕組み上GuardCFは.exeだけではなくリンクする.dllでもすべて有効になっていなければ効果が激減します。
win8.1 update以降であればwindows提供の.dllの大半はGuardCFがかかった状態で提供されていますが、サードパーティー製の.dllなどを使う場合、GuardCFが有効かチェックしてから使うとよいでしょう。
実際に作成してみたい場合、2015/04/01現在preview版であるVisualStudio2015の14.0.22609.0 D14REL以降を使う必要があります。
C/C++のコンパイルオプションに「/d2guard4」、Linkerのオプションに「/guard:cf」を追加してコンパイルすればGuardCFが有効な.exe/.dllを作成できます。
詳しくはFFRI様の記事を参照のこと。
次は具体的にどのようにして処理されているのかを説明しましょう。
まずコンパイル時に動的呼び出しされうるアドレスの一覧を作成する必要があります。
正式に資料に載っていたわけではなく動作から推測した内容ですが、仮想関数/dllexportした関数/&演算子などでアドレス取得された関数、のどれかに合致した物をすべてホワイトリストとして扱うようです。
次に実行時に呼び出すアドレスが確定するコードの直前に「guard_check_icallというホワイトリストに含まれるかを調べる関数」を呼び出すようコードを追加します。
次はリンクして.exeを生成する際にGuardCFにまつわる情報を付加します。
中身は、guard_check_icallで呼び出すアドレス格納位置、GuardCFのホワイトリスト、GuardCFの動作にまつわるフラグ、の3種になります。
これの詳細ついては後述します。
そして実行時、まず通常通り.exeをロードしますが、その際にguard_check_icallは通常のリロケーション処理に基づき、単にRETNするだけの関数へ向けます。
その後、win8.1 update以降である場合はGuardCF用情報を元に、guard_check_icallが呼び出す先のアドレスをどこに保持しているかを突き止め、それをntdll.guard_check_icall_fptrに変更します。
これにより、旧来のOS側の専用処理をいれることなく従来のロード処理だとチェックがスキップされ、win8.1 update以降でのみGuardCFが有効になるわけです。
次に実際のチェックです。
以下のうちどれかに合致すると実行してもよいと判断するようです。
そして、実行するべきではないと判断した場合は強制的にクラッシュして、被害を最小化する、という動作になります。
IMAGE_OPTIONAL_HEADER32内のDataDirectoryのIMAGE_DIRECTORY_ENTRY_LOAD_CONFIG(=10)に格納されています。
これはIMAGE_LOAD_CONFIG_DIRECTORY32構造体がそのまま入っていて、VC++2015以降であればGuard*というメンバーがあるのでそれを使います。
※GuardFlagsは0x58にあるのに14.0.22609.0 D14REL時点ではIMAGE_DATA_DIRECTORY上はsizeが0x40と出力されます、が、IMAGE_DATA_DIRECTORY.sizeが間違っているだけで、IMAGE_LOAD_CONFIG_DIRECTORY32.Sizeは正しい値なのでそちらを参照のこと。
以下各パラメーターの説明。
その他雑多にいろいろ書いておきます。
どうでしたでしょうか?
実はこれエクスプロイトを書きつつ学ぶWindowsセキュリティー機能 ~番外編SEHOP~の続編にするつもりだったんですが、/DYNAMICBASE:NOを指定するとなぜかGuardCFが働くなってしまい、どうしてもexploitがASLR回避に比重が置かれるため断念したという経緯で書かれたものになります。
そのためただ情報を列挙しただけで、読みづらい感じに……。
まぁそれでも人によっては役に立つ資料となるでしょう。
どうか、一人でも多くこういったセキュリティー機能に興味を持ってくれることを祈ります。
そして自分で書かなくてもググれば見つかる世の中になったらいいな。