妖精大戦争Ver1.00aで適当にいくつかバグ修正したパッチを作ってみた。
th128_bugpatch.zip
修正したバグ一覧
- プレイしたのとは異なるステージ・ルートとしてスコアが記録される
- リプレイを再生すると金(ノーアイス勝利回数)に加算される
- 左下の雪印と実際のボム個数が対応しない
なぜ作ったのかと聞かれると色々困るのだが、つい作りたくなったというかなんというか。
まぁ、悪いことではないよね、うん。
妖精大戦争Ver1.00aで適当にいくつかバグ修正したパッチを作ってみた。
th128_bugpatch.zip
修正したバグ一覧
なぜ作ったのかと聞かれると色々困るのだが、つい作りたくなったというかなんというか。
まぁ、悪いことではないよね、うん。
enum STAGE {
STG_INIT = 0, //定義上だけ存在
STG_A1_1,
STG_A1_2,
STG_A1_3,
STG_A2_2,
STG_A2_3,
STG_B1_1,
STG_B1_2,
STG_B1_3,
STG_B2_2,
STG_B2_3,
STG_C1_1,
STG_C1_2,
STG_C1_3,
STG_C2_2,
STG_C2_3,
STG_EX,
STG_A1_CLEAR,
STG_A2_CLEAR,
STG_B1_CLEAR,
STG_B2_CLEAR,
STG_C1_CLEAR,
STG_C2_CLEAR,
STG_EX_CLEAR,
};
struct result {
int score; // スコアを1/10したもの
char stage_no; // ステージID
char score2; // スコアの下一桁、なぜここにあるのかは不明
char name[9]; // 最大8文字、\0終端
char padding; // 常に0、おそらくコンパイラにより付加された物
time_t time; // 32bit unixtime、ここが0だと時間/ステージ/処理落ち率が---になる
char unknown[4]; // 常に0
float slowdown; // 処理落ち率、0.2はそのまま0.2%と表示される
char unknown2[4]; // 常に0
};
struct spell_result {
char name[128]; // 長さ0で????扱い
int no_damage; // 銀メダル
int no_ice; // 金メダル
int unknown; // 不明、到達回数?
int challenge; // 銅メダル
int unknown2; // 不明
int unknown3; // 不明
};
enumやら変数名は適当につけたけど、だいたいこんななはず。
メモリー上の配置は0x0443A5D8、確認してないけどイージーから順に10個ずつ並んでいるんじゃないかな。
スペルの方はルナティックのスコア少し下のほうにあった(正確なアドレスは忘れた)
さすがに何もやって無さ過ぎると思うので宣言とか。
目的:妖精大戦争のバグを直す!
とりあえず、リプレイ再生でノーアイス増えるのと、雪印がずれている問題は簡単だろうからやる。
他は出来たら。
22:00追記
リプレイでノーアイス増える問題は直せた。
次、雪印直す。
22:45追記
食らいボムで雪印更新されないバグも直せた。
次は、出来そうか調べながら考える。
01:25追記
別ルートにスコアが記録されるバグを直した。
そろそろ時間なので、これでリリースする。
解析改造というと普通はチートや有料版の制限外しなど不正利用がメインらしい。
これらの行為は未対策のソフトであれば解析改造の中でも一番簡単な部類ではあるし、入門にはうってつけなのだろうが、さすがにメインとして扱うのはどうかと思う。
少なくとも、解析が好きだというと必ずこれらの用途だと思わるのは理不尽だ。
実際のところ、解析改造は必要悪とでも思われている節があると思っている。
互換な別ソフトを作るため、ウイルスに対抗するため
こういった無くてはならない正当な理由があるため表立って非難は出来ないが、99%は悪い用途にしか使われない、だから使い手のことを疑うのは当然だ。
そして、それらの技術を学ぼうとする人も多くは、禁止されると逆に知りたくなる、といった気持ちが働いているように思えてならない。
けれど実際には、趣味で解析する様な人だっているし、既存アプリに機能を付け加える人や、バグ修正パッチを作る人だっている。
なぜ解析改造という時点で悪いイメージが付きまとうのだろうか?
むしろ、解析改造は悪として、規約や法律という時点から解析改造に対して不利な方向にばかり倒されていること自体がおかしいのではないだろうか?
開発者の権利を侵すことは確かにいけないし、それを守るのは正しい。
けれど、開発者と解析者でお互いの権利が衝突しうる状況下において、とりあえず開発者側に倒すといった方向性であることは確かだ。
だからこそ、解析改造といった行為は、たとえ善意を持った行動であろうとも法律や規約上は悪とされ、胸を張ることの出来ない後ろめたいものとなってしまっている。
要するに、解析改造では、悪いことしてなくても後ろ指差されたり、どんなにがんばってもグレーゾーンから出られなかったりするのが理不尽だああああああ
ってそれだけの話でした。
その1を見ていない人はその1から見始めることをお勧めします。
複数ファイルをまとめたファイルを作る場合、最低限どのような情報が含まれているべきでしょうか?
これは用途にもよりますが、おそらく今回入っているだろうと推測される情報は以下のとおりになります。
また、ファイルリストそのものの情報として、以下のようなものも必要でしょう。
今回のファイルリスト編ではこれらの情報全てを見つけることを目標とします。

srcから始まりtgaで終わっている文字列がほぼ確実にファイル名とわかるので、これを基点にして見ていきましょう。
まず各ファイル名の間のbyte数を数えてみると、全てきっちり20byteであることがわかります。
(ファイル名自体は可変長なようですが、その辺りはまた後で)
このことから、ファイル一つ辺りファイル名と20byteのデータが付いていることがわかります。
| addr | description |
|---|---|
| 0-? | 何かのファイル情報? |
| ?-? | ファイル名 |
| ?-? | 何かのファイル情報? |
次にファイル名の前後何byte目までがそのファイルに結びついている情報なのかを調べます。
ファイル末尾をみるとファイル名の後に8byteほどデータがくっついているのがわかります。
なので、ファイル名の前12byteとファイル名の後8byteがそのファイルの情報だと考えたくなりますが、
よく見てみるとどうやら違うらしいことがわかります。
まずファイル名の直後4byteを抽出してみると以下のようになります。
E4 69 00 00
3E 6C 00 00
75 6E 00 00
29 71 00 00
FB 73 00 00
B3 76 00 00
04 00 00 00
この並び方は明らかにリトルエンディアンなので、前後を前後を入れ替えると以下のようになります。
00 00 69 E4
00 00 6C 3E
00 00 6E 75
00 00 71 29
00 00 73 FB
00 00 76 B3
00 00 00 04
見てわかるとおり、徐々に増加傾向にあるそれなりに大きな数値であることがわかります。
ですが最後の4byteだけ明らかにその法則に反しており、不自然であることもわかるかと思います。
推測ではありますが、おそらくファイル末尾の8byteは個別のファイル情報とは関係のない情報であり、
ファイル情報はファイル名の前20byteということなのでしょう。
| addr | description |
|---|---|
| 0-19 | 何かのファイル情報? |
| 20-? | ファイル名 |
| addr | description |
|---|---|
| 0-7 | 何か情報? |
どうやらファイル末尾8byteが個々のファイルに言及したものではなさそうということはわかりました。
冒頭で挙げた情報のうち、ファイルそのものに関係しない情報といえば
の三つです。
では、8byteの中にこれらに該当するような情報が含まれていないか見ていきましょう。
目で見て数えたところ、上記三つの実際の値は
ファイルリストアドレス:0x0001E440
ファイルリストサイズ:0x07CF(1999byte)
ファイル個数:0x2B(43個)
でした。
そして、ファイル末尾の8byteは
04 00 00 00 0F 79 00 00
です。
予想外なことに、そのものずばりな数値はおろか近似値すら見当たりません。
ですが、他の情報が格納されているとも考えづらいため、何分の一かに除算された値である可能性を考えます。
たとえば、一般的な32bitCPUのOSが4GBのメモリーを管理するさい、領域を64KBごとに切り分けて2byteでサイズやアドレスを表現できるようにしているのと同じで
0xFFFFFFFFを超える表現を扱うが4byteで表現したい場合に4~64程度で除算された値が格納されていることがあります。
ファイル末尾8byteはおそらく30991(0x790F)と4の二つに分けられるように見えるので、これらの数値で除算してみましょう。
ファイルリストアドレス:0x7910(30992)
ファイルリストサイズ:0x01F3(499)余り3
ファイル個数:0x0A(10)余り3
ファイルリストアドレス:4余り4
ファイルリストサイズ:0余り1999
ファイル個数:0余り43
ファイルリストの先頭アドレスが非常に近い値をとっています。
またずれているのもたった4byteなのとファイルリストが伸びる方向なので
何か一つ二つ情報が格納されていると考えれば十分にありうる範囲です。
おそらく、ファイル末尾4byteはファイルリストの先頭アドレスを4で割った数値と思っていいでしょう。
また、4といえばすぐ横のファイル末尾4~8byte目に格納されていた数値でもあります。
おそらくですが、アーカイバ内でアドレス表記をするにあたって、何分の一の値を用いるか、という設定データなのではないかと思われます。
このファイル自体は4GBには遠く及ばないので本来ならば1が設定されているべきにも見えますが、おそらく実装の都合というやつなのでしょう。
| addr | description |
|---|---|
| 0-3 | アドレス表現の分母 |
| 4-7 | ファイルリストの先頭アドレス |
ファイルリストの先頭アドレスがわかったので早速見に行って見ましょう。
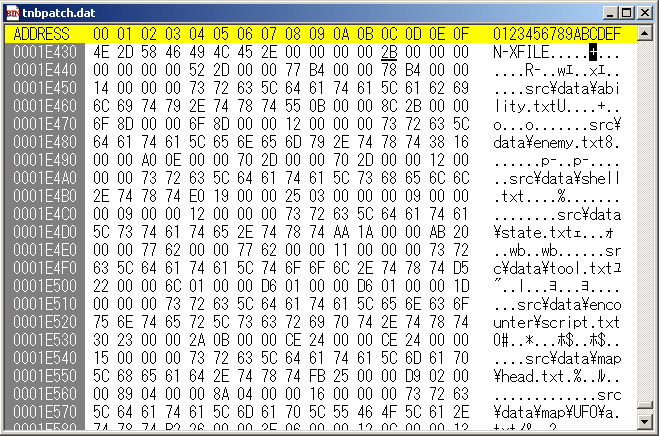
黒いカーソルが表示されている0x0001E43Cがファイルリストの先頭になります。
ただし、前章でも書いたように個々のファイルリストは0x0001E440から始まるので、0x0001E43C~0x1E43Fまでは個々のファイル情報ではないもののはずです。
これもまた前章で書いたようにファイル個数を手動で数えたものが0x2B(43個)でした、値が一致していることから見てファイル個数と見ていいでしょう。
| addr | description |
|---|---|
| 0-3 | ファイル個数 |
| 4~X | ファイル情報の配列 |
これで個々のファイルに関係しない情報三種は全て判明しました。
(アドレスと個数は言うまでもなく、ファイルリストのサイズもアドレスとファイル全体のサイズから計算可能です)
では個々のファイル情報に行きましょう。
| addr | description |
|---|---|
| 0-19 | 何かのファイル情報? |
| 20-? | ファイル名 |
まずファイル情報が可変である謎を解きます。
ファイル名をよく見ると終端記号(\0)がありません。
という事は、ファイル名の長さが明示されていなければ読み込むことが出来ないことになるので、20byteのうちどれかがファイル名のbyte数のはずです。
実際調べてみれば全てファイル名の直前4byteがファイル名の長さと一致していました、これがファイル名の長さでしょう。
| addr | description |
|---|---|
| 0-15 | 何かのファイル情報? |
| 16-19 | ファイル名の長さ |
| 20-X | ファイル名 |
次はファイルの格納アドレスを調べましょう。
その1で書いたように、このデータファイルは1byte目から格納ファイルの本体が始まっていました。
ということは、一つ目のファイルではファイル格納アドレスに0が入っているはずです。
実際ファイル情報の先頭に当たる0x0001E440を見ると0x00000000が格納されてました、以前ここの情報が徐々に増加していく傾向があったのもファイルの格納アドレスと考えれば説明が付きます。
ですが、一番最後のファイルでもここに設定された値は0x000076B3と、データファイル全体の1/4にも満たない値をとっています。
実際いくつかのファイルで4倍したアドレスを見てみれば、明らかにそこがファイル先頭だとわかるものばかりでした。
おそらくファイルリストの先頭アドレスと同じように1/4された値が格納されているのでしょう。
| addr | description |
|---|---|
| 0-3 | ファイル格納アドレス |
| 4-15 | 何かのファイル情報? |
| 16-19 | ファイル名の長さ |
| 20-X | ファイル名 |
次に圧縮後ファイルサイズ。
これは前後のアドレスの差と近似している値を探すだけなので簡単です。
先頭から一番目はアドレス0x00000000、二番目のアドレスは0x00000B55なので0x00000B55*4-0x00000000*4=0x00002D54となり
ちょうどファイル情報4byte目から4byteと一致します。
これが圧縮後ファイルサイズでしょう。
| addr | description |
|---|---|
| 0-3 | ファイル格納アドレス |
| 4-7 | 圧縮後ファイルサイズ |
| 8-15 | 何かのファイル情報? |
| 16-19 | ファイル名の長さ |
| 20-X | ファイル名 |
最後にファイルサイズです。
ですがもはや残っているのはたった8byteな上、前半4byteと後半4byteが全てのファイルで佐賀0~3以内の近似値を取っています。
また、後半4byte側が必ず前半4byte以上の値をとっています。
推測ですが、圧縮方法の都合で末尾に多少不要なデータが付着してしまうため、その不要データ込みのサイズと実際のサイズの二種類があるのでしょう。
要するに、前半4byteがファイルサイズで、後半4byteが解凍時使用スペースとなります。
| addr | description |
|---|---|
| 0-3 | ファイル格納アドレス |
| 4-7 | 圧縮後ファイルサイズ |
| 8-11 | ファイルサイズ |
| 12-15 | 解凍時使用スペース |
| 16-19 | ファイル名の長さ |
| 20-X | ファイル名 |
| addr | description |
|---|---|
| 0-3 | アドレス表現の分母 |
| 4-7 | ファイルリストの先頭アドレス |
| addr | description |
|---|---|
| 0-3 | ファイル個数 |
| 4~X | ファイル情報の配列 |
| addr | description |
|---|---|
| 0-3 | ファイル格納アドレス |
| 4-7 | 圧縮後ファイルサイズ |
| 8-11 | ファイルサイズ |
| 12-15 | 解凍時使用スペース |
| 16-19 | ファイル名の長さ |
| 20-X | ファイル名 |
以上のようにファイルリストの解析は完了しました。
次からはいよいよファイル本体の解析に着手します。
もちろんth123_aiはウイルスじゃありません、念のため。
一個前の版とか、手元でコンパイルしたものは引っかからなくて
あくまで現在最新版扱いで再配布されていたりする版だけが引っかかるという不思議。
たぶん、ウイルス検出判断に使われているバイナリコードの一部がたまたま合致したとかそういう話なんでしょう。
ただ気になるのは、特定のアンチウイルスソフトのみではなく、多数のアンチウイルスソフトから検出されている点。
単に、そのウイルスのみに見られるユニークなバイト列を検索して~なんてアルゴリズムであれば、ベンダーごとに検出に使うバイト列が異なるため、こんなにも色々なソフトで誤検出されることはないはず。
だからといって、処理の流れを読んでいるのなら前後のverが引っかかるはず。
単にファイルのハッシュを比較しているだけで、たまたま合致したとかそういう話なのだろうか?
それとも、アンチウイルスソフトに技術情報を提供している会社か何かがあって、そこが提示した情報を皆して使っているから複数で誤検出されたとか?
色々考えはするものの、どう考えても自力で対処できる話ではありません、本当に(ry
人付き合いの達人というか、苦労もせず他人と付き合えちゃう人に、ある種の共通点を見つけた気がする。
それは優先付けのようなもので、距離感とも計算高いともいえるようなもの。
たとえば、人にお願いされたとき、それを断るときと受け入れるときの按配が絶妙であるとか
人にお願いしたり押し付けたりするとき、それをしてもいいか悪いかの判断が絶妙であるとか。
つまり、表面上やその内容に関わらず、それが相手にとって大事なことであるか否か、といった判断が恐ろしく巧みなのだ。
その点、自分のように下手な人は、冗談を真に受けたり、本気の言葉を冗談と思って覚えもしない。
やはり、重要か否かの判別のうまさ、これが対人能力の高さをあらわす手っ取り早いものさしなのだろう。
といっても、優先付けの能力と一言で言っても、物事によってその内容は大きく変わる。
対人能力が高かろうと、コードリファクタリングの優先付けなどできようはずがないわけだ。
いったい何がどう影響し、対人能力としての優先付けを行う能力となっているのか?
誰に聞いても言葉を濁されるこれをいつか知ることが出来たらいいな。
黄昏フロンティアさまの6つのきのこの展開ツールを作ろうと
またも追加パッチだけ落としてきて見たわけですが
予想通り暗号化されていて、逆汗無しで暗号化データファイル解析やったるぞー!と意気込んでいたら
緋想天と同じフォーマットで、二次xor暗号の鍵を変えていただけだった、なんだこれ。
xor暗号は中身が推測できちゃえば鍵は容易に計算できるのだから
せめてメルセンヌツイスターの鍵を変えるべきじゃないのか……
という感じで、いい感じに出鼻をくじかれてやる気を持て余す中の人なのでした。
あ、ちなみに鍵は0xC5/0x89/0x49です。
メルセンヌツイスターの鍵も、ファイルフォーマットも変わってません。
その代わり見覚えのないcv4ファイルが追加されてました、cv2も展開できてないのがあったので微妙に変化あるのかもしれない。
とりあえず、次暇になったら適当にtouhouSEに仕込んで、まだ2ch書けたら投下してきますかね。