東方系dat展開ツールtouhouSE更新しました。
http://wordpress.click3.org/garakuta/touhouSE.zip
東方深秘録対応版です。
完璧主義が発動して、1方向hashからファイル名を逆算する作業に明け暮れたため、3週間ほど出すのが遅れました。
その甲斐あって98%のファイル名は判明しているので、その周りでは特に困ったりはしないと思います。
東方系dat展開ツールtouhouSE更新しました。
http://wordpress.click3.org/garakuta/touhouSE.zip
東方深秘録対応版です。
完璧主義が発動して、1方向hashからファイル名を逆算する作業に明け暮れたため、3週間ほど出すのが遅れました。
その甲斐あって98%のファイル名は判明しているので、その周りでは特に困ったりはしないと思います。
THxxBGMに深秘録製品版の曲再生機能を足すアプリを作りました(一応心綺楼も増える)。
http://wordpress.click3.org/garakuta/thxxbgmTh145Patch.zip
使い方は、中のwinmm.dllをTHxxBGM.exeと同じディレクトリに置くだけ。
うまいこと行けばpath設定に心綺楼と深秘録が増えて、該当ディレクトリを設定すれば聞けるようになるはず。
後置インクリメントと前置インクリメントは基本的に前置の方がよいそうですが、自分は後置の方が書きやすくて好きなので、どこまでなら後置でもいいのか検証する目的で速度を測ってみました。
検証に使用したコンパイラのバージョン:
VisualStudio C++ 19.00.22609 for x86
gcc (GCC) 4.8.1
clang version 3.6.0 (tags/RELEASE_360/final)
検証環境はWindows10 TechnicalPreview
典型的なfor文を前置後置それぞれのインクリメントを使用する形で作成。
インクリメント対象をunsigned int/iterator/適当に重めのクラスの三種それぞれを対象。
また、最適化により返り値計算が消えることを考えforの真偽判定でインクリメントの返り値を使用するものも用意。
以上をそれぞれ100,000,000回実行をさらに10回繰り返しかかった時間の平均をとる。
また、比較用に拡張forにてループまわすだけのも計測。
具体的なソースコードとコンパイルオプションは以下を参照。
ソースコード
コンパイルに使ったバッチファイル
以下読み飛ばしても通じる、検証をこの内容にした理由やらなんやら:
インクリメント演算子と言えば基本的にループで使用することが多いはず。
まれに+=1の代わりに使うこともありますが、それで行いうる処理はループも全て含んでいるでしょう。
他にも演算子オーバーライドなどでクラス独自に定義して使うこともあるかもしれませんが
そこまで行くと後置不利の根拠である値コピーがどーたらという前提すら崩れかねないですし
そもそも滅多にあるものでもないので今回は除外しました。
また、普通にforをまわすだけだと最適化で消え去ってしまうし、ある程度最適化を妨げようとすると今度はforが誤差になるぐらい処理速度を持って行かれてしまいます。
なので、インラインアセンブラでNOPを突っ込むことで対応。
それでもintのインクリメントをデクリメントに置換されたりいろいろしていますが、それは通常利用でも起きうるものとして許容しています。
クラス作成もいろいろ大変で、単にintをラップしたようなのを書くと当然ながら全部インライン展開されてint直と同じレベルまで最適化されてしまいます。
ですが、今回は後置の不利を検証するためなので残す必要があり、いい具合に重い処理として乱数を生成させました。
とはいえ乱数処理は重すぎるので1/1000しか動かないコードが入っています。
ちなみに、最適化の抑止の大変度合はclang>gcc>vcでした。
vcはNOP入れた以外では全部素直なコードを吐いて順当に遅かったです。
gccはクラスのインクリメントにて使いもしないメンバー配列をstd::copyしたら順当に遅くなりましたが、clangはそれすら最適化で消し去りました。
つまりclangが一番最適化は賢い、と思ったら最終的な計測結果ではgccに負ける感じに、詳しくは結果欄をどうぞ。
| vc++ | gcc | clang | |
|---|---|---|---|
| 拡張for | 57ms | 53ms | 48ms |
| int前置インクリメント | 46ms | 61ms | 41ms |
| iterator前置インクリメント | 47ms | 47ms | 45ms |
| クラス前置インクリメント | 320ms | 47ms | 316ms |
| int前置インクリメント、返り値使用 | 44ms | 47ms | 46ms |
| iterator前置インクリメント、返り値使用 | 44ms | 37ms | 46ms |
| クラス前置インクリメント、返り値使用 | 317ms | 51ms | 313ms |
| int後置インクリメント | 51ms | 44ms | 53ms |
| iterator後置インクリメント | 51ms | 50ms | 46ms |
| クラス後置インクリメント | 2206ms | 388ms | 446ms |
| int後置インクリメント、返り値使用 | 55ms | 50ms | 50ms |
| iterator後置インクリメント、返り値使用 | 97ms | 50ms | 54ms |
| クラス後置インクリメント、返り値使用 | 2253ms | 458ms | 431ms |
まず独自クラスは前置と後置で明らかに結果が異なり、後置が圧倒的に遅いです。
最小のclangでも1.5倍、最大のgccだと実に約9倍。
もちろんこれはコピーコンストラクタの重さに依存しますが、ある程度以上のクラスであれば必要のない後置インクリメントは避けた方がよさそうです。
また、地味ですがvc++のみ返り値使用の後置iteratorが前置の約2倍かかっています。
vc++においてはまだ「iteratorは最適化すれば消え去る」は幻想のようですね。
返り値の使用有無による変化は例外を除いて後置のクラスでのみでした(例外:前述のvc++後置iterator)。
おそらくintやiteratorであれば最適化の結果前後が消え去り、通常のメモリ=>レジスタ移動の範囲で解決できてしまうからでしょう。
なぜかgccだけクラス使用時の速度がとても速いです。
が、試行錯誤している間はずっとclangの方が速かったので、偶然今のコードではインスタンスが全部レジスタに載ったとかだと思われます。
ただしvc++がクラス使うと遅いのは最初から最後まで一貫していたので、この三つの中で一番遅いことは確定してよさそう。
他は特に速度の変化は見られません、また拡張forとの速度差も見られません。
なので、後置インクリメントでもプリミティブ型かiteratorなど薄いラッパークラスであれば速度に影響が出ることはない、と言っていいと思います。
(例外:vc++で後置インクリメントの結果を使う)
それ以外で後置インクリメントを使うこと自体そうあることではないですし、別に後置インクリメントをつける癖がついていても害はないと言っていいでしょう、あーよかった。
前回せっかくclangやgccの環境を整えたので、以前から気になっていたインクリメントの速度計測をやってみました、いかがだったでしょうか。
個人的には後置の方が書きやすくて好きなので、現代の最適化の力を使えば特に害はなさそうとわかって一安心でした。
次はまた何かの速度計測をやるかもしれませんし、何かアプリ作るまで放置かもしれません。
ではまた。
本の虫さんの記事にて
linux上のGCCではただ別の関数へフォワードするだけの関数をコンパイルしてもPICが有効だとjmp一文にならない事とその理由を説明した記事を翻訳したものが載った。
そこでふと疑問に思ったのだが、PICとか関係のないwindows上ではどうなっているのだろうか?
というわけで、GCCとclangとVisualStudio2015それぞれでコンパイルして結果をまとめてみた。
なお、最適化の結果消え去るならば問題ないはずとの考えから最適化OFF/ON両方で検証している。
検証に使用したコンパイラのバージョン:
VisualStudio C++ 19.00.22609 for x86
gcc (GCC) 4.8.1
clang version 3.6.0 (tags/RELEASE_360/final)
まずは検証に使うソースコードを載せる。
main.cpp
#include <iostream>
void OtherFile();
void TailProc();
void NormalProc() {
std::cout << "Normal\n";
}
void CheckOtherFile() {
OtherFile();
}
void CheckTailProc() {
TailProc();
}
void CheckNormalProc() {
NormalProc();
}
void TailProc() {
std::cout << "Tail\n";
}
int main() {
CheckOtherFile();
CheckTailProc();
CheckNormalProc();
return 0;
}
lib.cpp
#include <iostream>
void OtherFile() {
std::cout << "OtherFile\n";
}
一応解説しておくと、CheckOtherFileは定義が別の.cpp、CheckTailProcは同じ.cppだが後方で宣言、CheckNormalProcは前方で宣言となっている。
コンパイルに使用した.bat
cl /EHsc /Ox /GL /Fevc_exe.exe main.cpp lib.cpp cl /EHsc /Od /Fevc_exe_O0.exe main.cpp lib.cpp g++ -O3 -flto -o gcc_exe.exe main.cpp lib.cpp g++ -O0 -o gcc_exe_O0.exe main.cpp lib.cpp clang++ -O3 -o clang_exe.exe main.cpp lib.cpp clang++ -O0 -o clang_exe_O0.exe main.cpp lib.cpp
clangのみ手元ではリンク時最適化できなかったため通常の最適化のみ。
最適化OFFの場合
main

各チェック関数
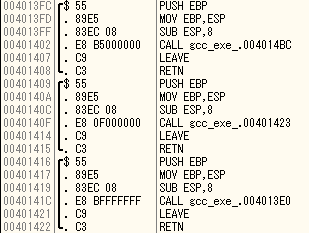
mainでなぜかcallが四つあるが一つ目おそらくコンパイラがつけた特殊関数だと思われる。
問題のcheck部分は元の記事ほど悪くはないがjmp命令ひとつまで縮んでいない。
最適化ONの場合
main
各チェック関数は三つとも完全にインライン展開されている。
最適化OFFの場合
main

各チェック関数
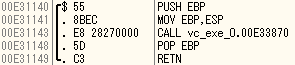
チェック関数は三つともほぼ同じだったため他二つは割愛。
最適化ONの場合
main
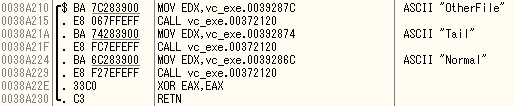
三つとも完全にインライン展開されている。
最適化OFFの場合
main
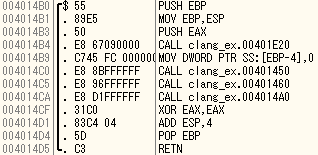
各チェック関数
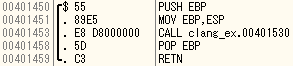
mainの一つ目のcallはgccと同じくコンパイラが付与したもの。
チェック関数は三つともほぼ同じだったため他二つは割愛。
最適化ONの場合
main

OtherFileだけインライン展開されていないが、それは前述のとおりリンク時最適化が入っていないためと思われる。
CheckOtherFile自体はインライン展開されている。
windows上だとVC++/gcc/clangのどれであっても、フォワードするだけの関数をjmp一文に翻訳してくれたりはしない。
だが、最適化を有効にすればどのコンパイラでも、別の.cppでも同じ.cppでも、大体インライン展開されてほぼコスト0になるので気にする必要はほぼない。
VC++ではjmp一文にならないのは知っていたが、記事を読んだ範囲ではgccがjmp一文に翻訳するとしかおもえなかったため、コンパイラ比較にいい題材だろうと試してみた結果
このようなどれも結果がほぼ一緒で大した価値のない比較記事が生まれることとなりました、なんてこったい。
一応clangが文字数情報を生成してくっつけてくれてるとか、VC++はmainはほぼ書いたまんまだけどその他は前後にちょっと追加があるとか、clangのフォワード関数部分はgccではなくVC++寄りだとか、見どころはないでもないが全部本題とは無関係である。
まぁ、可読性のために別関数にしたりするぐらいではそう滅多にオーバーヘッドは生まないことが分かっただけでも収穫だろうか。
なにか間違いなどありましたらコメントください。
ではまた。
Windows8.1 updateから入ったセキュリティー機能であるControl Flow Guard(以降GuardCF)について調べたのでまとめておきます。
本記事を書く上で、以下のサイトを参考にさせていただきました。
http://www.ffri.jp/blog/2015/01/2015-01-05.htm
IMAGE_OPTIONAL_HEADER32など本稿にあまり関係のない部分については特に解説しないので、必要なら別途ググるなどしてください。
ざっくりと説明すると「呼び出す関数が実行時に決定されるコードから呼び出せるアドレスをホワイトリストで管理し、それ以外を実行しようとしたらクラッシュする機能」です。
たとえばC++の仮想関数、dllを動的リンクした際のGetProcAddressの返り値、関数ポインターを経由した呼び出し、などなどが対象。
主に、仮想関数テーブルを上書きすることで仮想関数実行時に任意のアドレスを実行させる、俗にいうvtable overwriteを防ぐための機能です。
パスの解析やらは一切やっておらず、バグか脆弱性がない限りここではAは呼ばれないと自明な場合でも、Aがホワイトリストに入っていればAの呼び出しを許可してしまいます。
おそらくこれは速度的な都合か、キャストを駆使されると確実な追跡が難しいというあたりかと。
また、仕組み上GuardCFは.exeだけではなくリンクする.dllでもすべて有効になっていなければ効果が激減します。
win8.1 update以降であればwindows提供の.dllの大半はGuardCFがかかった状態で提供されていますが、サードパーティー製の.dllなどを使う場合、GuardCFが有効かチェックしてから使うとよいでしょう。
実際に作成してみたい場合、2015/04/01現在preview版であるVisualStudio2015の14.0.22609.0 D14REL以降を使う必要があります。
C/C++のコンパイルオプションに「/d2guard4」、Linkerのオプションに「/guard:cf」を追加してコンパイルすればGuardCFが有効な.exe/.dllを作成できます。
詳しくはFFRI様の記事を参照のこと。
次は具体的にどのようにして処理されているのかを説明しましょう。
まずコンパイル時に動的呼び出しされうるアドレスの一覧を作成する必要があります。
正式に資料に載っていたわけではなく動作から推測した内容ですが、仮想関数/dllexportした関数/&演算子などでアドレス取得された関数、のどれかに合致した物をすべてホワイトリストとして扱うようです。
次に実行時に呼び出すアドレスが確定するコードの直前に「guard_check_icallというホワイトリストに含まれるかを調べる関数」を呼び出すようコードを追加します。
次はリンクして.exeを生成する際にGuardCFにまつわる情報を付加します。
中身は、guard_check_icallで呼び出すアドレス格納位置、GuardCFのホワイトリスト、GuardCFの動作にまつわるフラグ、の3種になります。
これの詳細ついては後述します。
そして実行時、まず通常通り.exeをロードしますが、その際にguard_check_icallは通常のリロケーション処理に基づき、単にRETNするだけの関数へ向けます。
その後、win8.1 update以降である場合はGuardCF用情報を元に、guard_check_icallが呼び出す先のアドレスをどこに保持しているかを突き止め、それをntdll.guard_check_icall_fptrに変更します。
これにより、旧来のOS側の専用処理をいれることなく従来のロード処理だとチェックがスキップされ、win8.1 update以降でのみGuardCFが有効になるわけです。
次に実際のチェックです。
以下のうちどれかに合致すると実行してもよいと判断するようです。
そして、実行するべきではないと判断した場合は強制的にクラッシュして、被害を最小化する、という動作になります。
IMAGE_OPTIONAL_HEADER32内のDataDirectoryのIMAGE_DIRECTORY_ENTRY_LOAD_CONFIG(=10)に格納されています。
これはIMAGE_LOAD_CONFIG_DIRECTORY32構造体がそのまま入っていて、VC++2015以降であればGuard*というメンバーがあるのでそれを使います。
※GuardFlagsは0x58にあるのに14.0.22609.0 D14REL時点ではIMAGE_DATA_DIRECTORY上はsizeが0x40と出力されます、が、IMAGE_DATA_DIRECTORY.sizeが間違っているだけで、IMAGE_LOAD_CONFIG_DIRECTORY32.Sizeは正しい値なのでそちらを参照のこと。
以下各パラメーターの説明。
その他雑多にいろいろ書いておきます。
どうでしたでしょうか?
実はこれエクスプロイトを書きつつ学ぶWindowsセキュリティー機能 ~番外編SEHOP~の続編にするつもりだったんですが、/DYNAMICBASE:NOを指定するとなぜかGuardCFが働くなってしまい、どうしてもexploitがASLR回避に比重が置かれるため断念したという経緯で書かれたものになります。
そのためただ情報を列挙しただけで、読みづらい感じに……。
まぁそれでも人によっては役に立つ資料となるでしょう。
どうか、一人でも多くこういったセキュリティー機能に興味を持ってくれることを祈ります。
そして自分で書かなくてもググれば見つかる世の中になったらいいな。
.dllや.exeでimportしている外部関数一覧を表示するアプリ作りました。
http://wordpress.click3.org/garakuta/dll_import_list.zip
詳細ページ
静的リンクでどんな.dllにリンクしていて、どんな関数を実行しているかを調べるアプリ。
自分なんかが作らなくてもその辺にごろごろしてそうだが、単に手元のHDD上にしか存在していなかったので、バックアップを兼ねて公開してみただけ。
Jane Styleの広告をブロックするアプリ作りました。
http://wordpress.click3.org/garakuta/jane_style_ad_block.zip
詳細ページ
ほとんど自分用、もしくはバイナリエディタとか使えない初心者向け。
巷では1byteのバイナリパッチで広告ブロックする手法が出回っていますが、毎回解析したりするのがだるそうだったので
機械語にパッチあてずに何とかして、exeが更新されてもよっぽどじゃないと動くようなのを目指して作りました。
zip作って放置するだけだった自作物を一覧できるようにしました。
自作物一覧
一応サイト右上のリンクからも飛べます。
2015/03/16現在全部で63個あります。
また、せっかくなので過去バージョンのダウンロード機能つけたり、一言説明つけたり、ダウンロードせずにReadmeやソースコード閲覧できる機能つけたりもしてあります。
atomのフィードも自作物一覧全体と個々の自作物ごとでそれぞれ備えているのでフィードリーダーガチ勢でも安心。
.pngから.cur(マウスカーソルとかのアレ)を作成する小物アプリ作りました。
http://wordpress.click3.org/garakuta/png2cur.zip
元々は友人の手伝いで作った小物なのであんまり実用性はない。
が、それでも一応作ったものなので、適当にreadmeとかこさえて公開しとく事にしました。
(いないと思うけど).curを大量作成する必要に駆られている人とかいたらどうぞ。
花枕杯に参加してきました。
これは花AI塚というツールを使い、東方花映塚上で動作するAIを実装し戦わせ最強を決めるコンテストです。
自分の総合順位は5位、ただし参加者総数は5人、つまり最下位でした。
まぁ結果は散々でしたが、参加はしたのでその感想とか、参加したAIの解説とか、そういうことを書いておこうと思います。
参加したAIはこちら。
名前:縦移動禁止花AI@メディスン
http://wordpress.click3.org/garakuta/tate_kinshi_hana_ai.zip
ひとまず.zipの中に入れた解説を丸ごとペタリ。
縦移動を封印し、横移動だけに特化してそこそこ戦えるようにしたAI。
別になめプではなく、余裕こきすぎて24時間しか作業時間が取れなかったため、
実装内容を絞って時間対効率の最大化を図ったためこうなった。アルゴリズムも最初考えていたものが処理速度上不可能と発覚したので即興。
その割には結構いい線いってると思うが現実は如何に。@メディスンとあるが、別に専用カスタマイズされているわけではなく、誰でも動く。
単に作者がメディスン好きなだけである。
メディスンかわいいよメディスン。一応LunaAI相手でもラウンド取れることもあるぐらいにはちゃんと戦える。
※ただし咲夜さんと映姫様除く。仕組み:
自身のy座標一列分の配列(以下危険度マップ)を作り
弾や敵などに対し、そのy座標に到達するまでにかかる時間と、到達したときのx座標を算出。
その周囲を到達までの時間で埋めるを繰り返す。すると、弾が到達するまでにかかる時間が長いx座標ほど安全という理屈により、
どの辺のx座標を目指せばいいかがなんとなくわかるので、
あとはそれを念頭に置いて移動したり色々するだけのAI。一応軽いキャラ対策などは入れたが、後述の弱点のように問題点は多い。
それ以外にも、粒弾相手でも被弾してしまうようなコーナーケースのつぶしは足りないし、
長期的展望による回避行動もとらないし、C2の運用やコンボなど改善の余地はたくさんある。弱点:
当然ながら縦には移動しない(というか後ろの弾がまったく見えていないので出来ない)ので、
咲夜さんのC2/C3は撃たれたら真横弾で落ちるのは確定。
映姫様の自機狙いレーザーの対策をとっていないので、されるとあっという間に死ぬ。
文さんのExは判定強いくせに早いので、ちょっと周囲の弾配置が悪いとすぐ詰む。
ルナサを相手にすると後ろから弾が飛んでくるため運ゲー化する。
チルノはパーフェクトフリーズで背後の弾がこっち向かってくると避ける手段がない。
ミスティアは未対策なので、チャージアタックの弾源に重なり落ちる光景がよく見られる。
てゐさんは中央からちょっと外れるとExの軌道に巻き込まれ、そのまま壁と挟まれて死ぬ。
中でも書いてある通り本体の実装に取れた時間がエントリー最終日である1月31日の24時間しかなかったため、突貫作業で実装されたAI。
時間がなくなった理由はこれとかこれのせい。
それ以外にも仕事で休日出勤が4日ほどあった。
まぁ期日が決まってるものがあり、不測の事態もありうるのに、他にかまけていた自分が悪いという話でした。
さてAIですが、最初は縦移動封印などする気はなく、まったく別のアルゴリズムで作るつもりでした。
画面全域を表す二次元配列を作り、そこの弾の予想軌道上に「到達までにかかる時間によって減算される危険度」を設定し、そこから判明する付近の安全領域に向かって移動する、という感じ。
単純にこれだと計算量がとんでもないことになると予想は出来ていたので、対象の弾を自分の周囲に限定したり、弾や自機のxyを割る5した値を使うなど軽量化案はいくつか考えていました。
だが現実は予想以上に厳しかったのです。
なんと300*450(ゲーム内の移動可能範囲+α)の配列をローカル変数として定義しただけで、体感してわかるほどの強烈なラグが。
調査の結果、テーブルのリサイズがありえないほど重いようで、事前に値をつめておいて更新するだけならそれほどでもないことが分かったのですが、自分はこの事件で心が折れてしまいました。
なので、処理速度が問題にならないぐらい軽いアルゴリズムを検討するところから始めることになります、ちなみにこの時1月31日の午前5時5分(エントリー締め切りは1月31日24時00分)。
そこで考えたのが、自分は普段どうやって弾幕を避けているのか。
最初のアルゴリズムの軽量案である”xy割る5″も、自分がプレイするときは1ピクセル単位で見ているわけではなく、もっと荒い単位でとらえているはずだという点からきているからです。
そこで気づいたのが、避けるだけなら最下段に張り付いて、基本的に左右移動だけでなんとかしている、という事実。
実装に割ける時間も少なかったので元から攻撃に関することは諦めようとは思っていました、なので縦の移動を封印し横移動だけに特化すれば、簡単かつ高速に動作するAIが作れるのではないか、と。
考えている時間はありません、なので自分はこの閃きに賭けることにしました。
さて、横移動にだけ限ると言ってもアルゴリズムはいくらでも考え付きます、だがそんなのをまともに検討している時間はありません。
なので初案のアルゴリズムをそのまま横一列に限って使うことにしました。
これは単純に危険度マップのサイズを減らすだけに留まらず、考慮するべきフレーム数問題をも解決しています。
なぜならば、弾がそのy座標を通過する1フレームだけ考慮すれば基本的に十分だからです。
後に、実際には弾の大きさを考慮して前後数フレームは検討しなければならないことに気づきますが、それでも初案に比べれば劇的な高速化でした。
(画面全域、全弾対象、xyを整数に切り上げただけの値を使用、10フレーム先まで計算、と比較すると単純計算で実に1/4500の計算量)
ちなみにこの時午前5時22分。
この後は特に面白い話はなくて。
ひとまずベースの実装を終え(7時15分)
Easyにすら負けるレベルでバグバグだったのでひたすらCPUと対戦してバグをつぶし(10時16分)
朝ご飯を食べ(11時23分)
拡張にかかるコストが大きくなりすぎたのでリファクタをいれ(13時05分)
※この時点で自分では勝てない強さに到達してます、とはいえ自分は花はとても弱い(花Exが安定せず、クリアできたことが過去二回しかない)のであまり参考になりませんが。
LunaCPU相手にひたすら勝負を挑み被弾したら原因を調べて潰すを繰り返し(16時11分)
キャラごとの個別対策をひたすら入れ(21時52分)
全キャラ相手に一戦してそれだけで勝負が終わるほどの致命的バグがないことを確認し提出した(23時26分)
その後は
エントリー人数や使用キャラなどが公開され(02月01日 01時02分)
就寝(01時21分)
花枕杯開始(14時00分)
花枕杯終了(16時00分)
起床して最下位だということを知る(18時54分)
となっています。
さて、AIの解説に戻りましょう。
本AIで縦移動禁止や作成にかかった時間を除く大きな特徴として、マイクロスレッド上に実装されいるというものがあります。
マイクロスレッドというのはコルーチンやファイバーの親戚で、実態はシングルスレッドですがまるでマルチスレッドのように使え、なおかつスレッドの切り替えタイミングを自身で決められる仕組み、です。
これにより、1フレームに一回だけ実行する処理を簡潔に書けたり、フレームをまたいでもローカル変数を維持しておけたり、といった恩恵を受けられます。
と言ってもこれはあれば便利程度の物で、AI作成では大して重要でありません。
ですが、私はマイクロスレッドをとても愛好しているので導入しました(私制作のAIツール3種すべてでマイクロスレッドが提供されているのもそのため)。
マイクロスレッドはmy_lib.lua上に実装されていて、create_([head|tail]_)?threadで作成、yield関数を呼び出すと次のマイクロスレッドに実行が移り、すべてのマイクロスレッドが一度ずつ実行されると次のフレームへ進む。
headやtailはマイクロスレッドの中での実行順序を指定するための物で、headで作られたものはそうでない物すべてよりそのフレーム内で先に呼ばれる、tailは逆に後に呼ばれる。
たとえばtailはキー操作に使われており、他のスレッドでキー操作をしたくなったらグローバルの配列上にポンポン投げ入れ、tailのマイクロスレッドでその結果を一つにまとめてsendKeys関数に渡している。
花枕杯は非常に楽しかった。
一時期TopCoderをやっていた時も思いましたが、参加者たちがさまざまな方法論でプログラムを作成し、それらを競わせるというものは知的遊戯として非常に面白い物です。
結果は残念なことに最下位で、それ自体は非常に悔しいのですが、そういう感情すらただプログラムを書いているだけでは味わえないもので、醍醐味の一つだと思います。
本選をリアルタイムで見れなかったのは地味に凹みました。
いや前日に30時間以上連続で起きていたのだから当然ではあるのですが、なぜ14時までに起きられなかったのか……。
自分が独自アルゴリズムで参加したのは、作業時間的に劣る自分が勝てるとしたらアルゴリズムで優るしかないという思いからだったのですが、結果だけ見るとそんなことしない方が結果は良かったかもしれません、反省。
だけど、自分のAIの弱さがまるでアルゴリズムが劣るせいととられていそうなのが心残り。
なので、次回があればこのAIの正当進化系で参加しようと思っています。
もしかしたら次回を待たずに余暇で改良して公開するかもしれないですが、その時は適当に遊んでこいつ相変わらず弱いなーなどと楽しんでください。
それと作者さんが参加者の一人だったせいか、期間中に花AI塚にバグが次々と見つかり日々修正されていくというのもなかなかに面白い事態でした。
花AI塚のソースコードが公開されていたりすると、原因行数まで特定してのユーザーによるデバッグも行われてさらに楽しそうですが、ツールの性質上花映塚の対人チートに利用できるため無理なんですよね、残念。
実はAI提出時点では自分はエキシビジョンの存在をすっかり忘れていました。
提出時に主催であるろくしーさんさんに聞かれて思い出したものの、そこから実装を変更するには時間が足りず、そのまま提出することになりました。
結果はエキシビジョンも同点最下位、まぁ当然ですね。
一応最下位のもう一方は被弾時以外C1しか使わない妖夢AIさんであったため、もし最下位決定戦が成立していたら勝てたのかもしれませんが、お互いにエキシビジョン専用処理なしなので所詮どんぐりの背比べですかね。
最後に、主宰のろくしーさん、ツール開発の@ide_anさん、自分以外の参加者さん、とても楽しかったです、ありがとうございました。