この記事は、同人サークル「特殊装甲隊」様作成の東方二次創作ゲーム「テンドーブレード」のファイルフォーマットを解析した際のまとめです。
本記事内に書かれたすべての文章の責任は「他人の空似」管理人にあり、「特殊装甲隊」様のサークル代表であるNnP氏は一切関係ありません。
また、本記事は「特殊装甲隊」様およびNnP氏の許諾を得ずに記述したものであり
テンドーブレード動作確認版および修正パッチおよび「特殊装甲隊」様サークルホームページのどこにもリバースエンジニアリングについての記載がなかったことを根拠として記述したものです。
問題があると思われる場合、コメント欄までご連絡をお願いします。
(非公開ブログでまで何書いてるんだろうね、自分。)
発端
東方改造スレにて要望があがっていたのを見かけたのが発端。
本来ならばすぐにでも投下したいぐらいなのだが、規制により書き込めないので断念。
他と違って改造スレは2chにあるからね、しょうがないね。
前提
製品版は手元にない。
動作確認版および修正パッチから解析した。
また、exeファイルに対して起動および逆アセンブラなどによる解析は一切行っていない。
(いわゆるバイナリエディタのみを使ったファイルフォーマット解析)
始めのいろいろ
製品版を持っていないのでまず解析可能か否かから検討したりとか、解析にHaskellを使おうとしてみて諦めたりとか、そういった細かいイベントがいくつかありましたが、関係ないので省略。
バイナリを適当に眺めてみる@ヘッダ編
まず、パッチに付属しているtnbpatch.datをバイナリエディタで開いてみます。
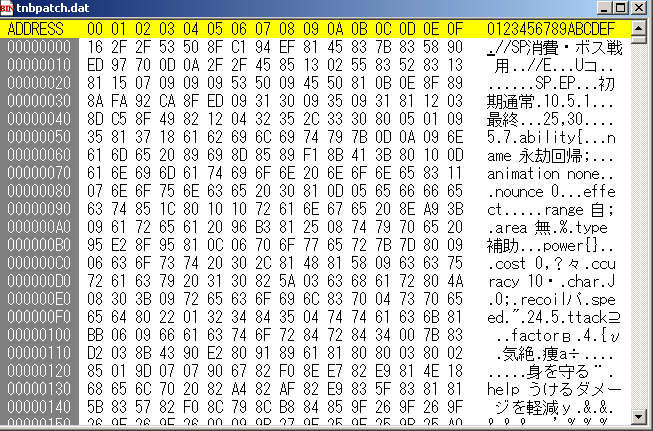
まず目に付くのは、
* いきなりデータ部と思わしきものが始まっている
* 目に見える形で文字列が残っている
* 通常文字列とバイナリが入り乱れている
この3点です。
では、順に推測していきましょう。
いきなりデータ部が始まってる
なぜいきなり生のデータが並んでいてはおかしいのか。
それは、ファイルの情報がヘッダとして付いているはずなのに見当たらないから、です。
対象とするファイルはアーカイブファイル(複数のファイルをまとめたもの)だと推測されるので当然ファイルとしての情報(ファイル名、ファイルサイズなど)が保存されているはずです。
さらにいうなら、実データより先に手に入れることが可能なように格納されているはずなのです。
なぜなら、基本的にデータファイルは巨大であり、常時メモリー上に配置してはおけないためで
アプリはファイルのリストだけを保持しておき、必要に応じて読み出す形で運用するのが通常想定される使用法だからです。
ですが、このファイルは2byte目からはどう見てもテキストデータにしか見えないデータが続いています。
つまり、このファイルにはヘッダとしてファイル情報が付いていないものだと判断せざるをえません。
とすればおそらくファイルの情報はフッタ(ファイル末尾に位置するデータ)から引けるようになっているのでしょう。
まだ手元の情報だけでは推測できないので、この場はとりあえずファイル情報に関してはスルーして次に進みます。
目に見える形で文字列が残っている
データファイルには暗号化がかかっていることが多々あります。
その場合、データファイルをバイナリエディタで開こうとも意味のある情報は拾えないのが普通です。
少なくとも、ここまであからさまに読み取り可能な文字列が並ぶことはありえないと断言してもいいでしょう。
一応、読み取り速度が重視されるファイルなので暗号化がかかっていない恐れもありますが
基本的にこのサイズのファイルでそういったことが重視されて暗号化が解かれることはありえません。
さらにいうならば、このファイルは圧縮されていると推測されるため(後述)、もし速度が重視されるならば圧縮もされていないはずです。
なので、このファイルは少なくともデータ部に関しては暗号化をしていないと推測できます。
通常文字列とバイナリが入り乱れている
これはある種の圧縮ファイルによく見られる特徴で、バイト単位で入出力する圧縮アルゴリズムを用いたデータだと推測されます。
たとえばdeflate(標準的なzipファイルの圧縮アルゴリズム)であれば、データはビット単位のストリームとして処理され
基本的に人が読める状態のデータは残りません。
また、生データであれば非テキスト文字が入る事は基本的にありえません、ましてや文章の途中で断ち切れるわけはないでしょう。
なので、こういう形のデータが残るとすれば
バイト単位で入出力し、圧縮しても短くならないデータはそのまま生に書き出し、短くなるデータは圧縮データで置き換える。
そんなアルゴリズムで圧縮されたデータぐらいしかありえません。
おそらくは辞書参照方式かそれに類するアルゴリズムによるものでしょう。
とりあえずこの場はここまでにして先に進めます。
バイナリを適当に眺めてみる@フッタ編
ファイルの先頭を眺めた結果、おそらくファイル末尾に何かしらの情報が付加されていることがわかりました。
なので、今度はファイル末尾をざっと眺めてみましょう。

予想通り、ファイル名やファイルサイズらしき情報がリスト状に並んでいます。
どこまで続いているのか追ってみたところ、だいたい0x0001E440ぐらいまで続いていました。
ファイル情報が一個当たり大体45byte前後で並んでいるので、大体45ファイルぐらい格納されている計算です。
おそらくこれがファイルリストと見て間違いないでしょう。
また、ファイル名を見た範囲ではデータの断片化やバイナリと文字列の混同などは見られないため
ファイルリストは圧縮も暗号化もかかっていないことがわかります。
問題はフッタのサイズやファイル数といった情報がざっと見では見当たらないことですが、
この件については後で考えるとして、この場はファイルリストの所在が判明しただけでよしとすることにします。
その1まとめ
まだざっと眺めた段階ですが、この段階でもわかったことはかなりの量にのぼります。
いったんまとめてみましょう。
* ファイルリストはフッタに格納されている
* 暗号化はかかっていない
* データ部のみ圧縮されている
* 圧縮アルゴリズムは辞書参照方式かそれに類するもので、バイト単位で入出力できるよう実装されたもの
* 大体45ファイルぐらい格納されている。
推測を多分に含んでいるので一つ位外れているかもしれませんが、大体概要はつかめたといっていいでしょう。
その2ではファイルリストの詳細を詰めていきます。